 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
FAMIE: A Fast Active Learning Framework for Multilingual Information Extraction
Feb 16, 2022
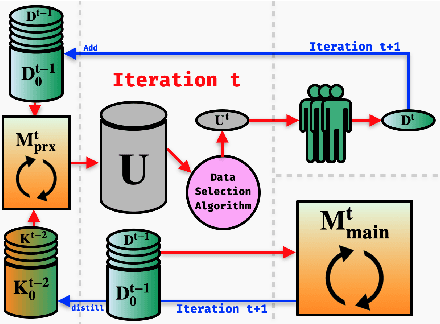

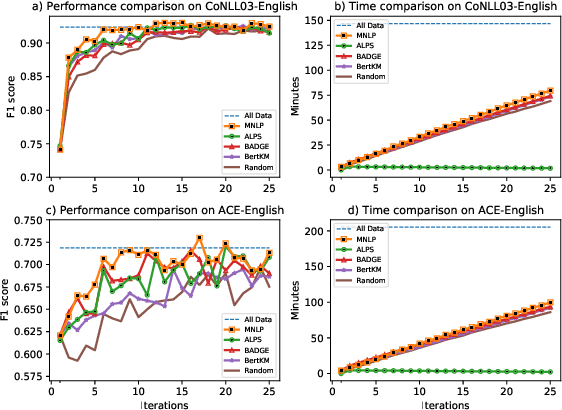

This paper presents FAMIE, a comprehensive and efficient active learning (AL) toolkit for multilingual information extraction. FAMIE is designed to address a fundamental problem in existing AL frameworks where annotators need to wait for a long time between annotation batches due to the time-consuming nature of model training and data selection at each AL iteration. This hinders the engagement, productivity, and efficiency of annotators. Based on the idea of using a small proxy network for fast data selection, we introduce a novel knowledge distillation mechanism to synchronize the proxy network with the main large model (i.e., BERT-based) to ensure the appropriateness of the selected annotation examples for the main model. Our AL framework can support multiple languages. The experiments demonstrate the advantages of FAMIE in terms of competitive performance and time efficiency for sequence labeling with AL. We publicly release our code (\url{https://github.com/nlp-uoregon/famie}) and demo website (\url{http://nlp.uoregon.edu:9000/}). A demo video for FAMIE is provided at: \url{https://youtu.be/I2i8n_jAyrY}.
A Unified Framework of Medical Information Annotation and Extraction for Chinese Clinical Text
Mar 08, 2022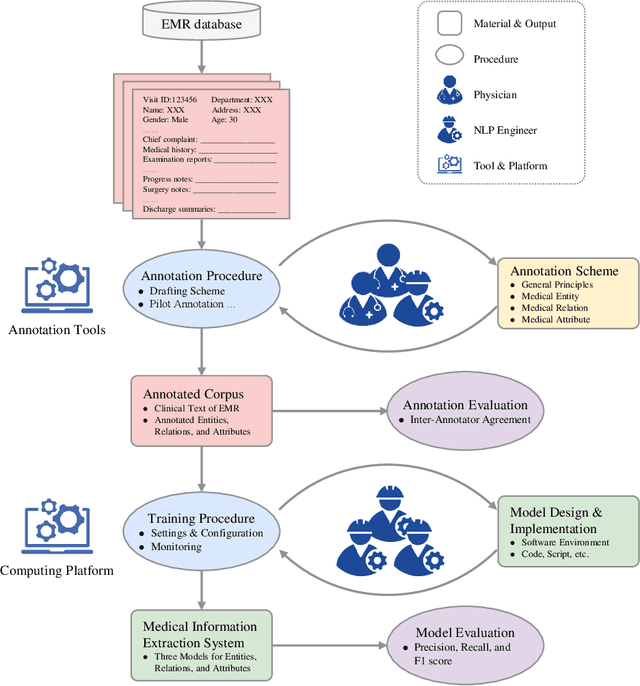
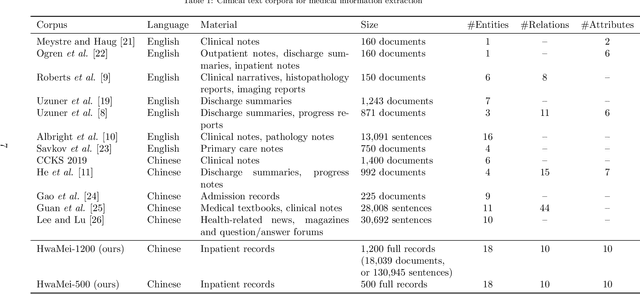
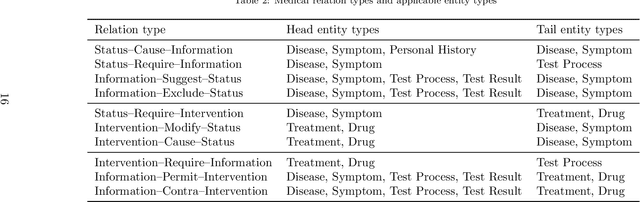
Medical information extraction consists of a group of natural language processing (NLP) tasks, which collaboratively convert clinical text to pre-defined structured formats. Current state-of-the-art (SOTA) NLP models are highly integrated with deep learning techniques and thus require massive annotated linguistic data. This study presents an engineering framework of medical entity recognition, relation extraction and attribute extraction, which are unified in annotation, modeling and evaluation. Specifically, the annotation scheme is comprehensive, and compatible between tasks, especially for the medical relations. The resulted annotated corpus includes 1,200 full medical records (or 18,039 broken-down documents), and achieves inter-annotator agreements (IAAs) of 94.53%, 73.73% and 91.98% F 1 scores for the three tasks. Three task-specific neural network models are developed within a shared structure, and enhanced by SOTA NLP techniques, i.e., pre-trained language models. Experimental results show that the system can retrieve medical entities, relations and attributes with F 1 scores of 93.47%, 67.14% and 90.89%, respectively. This study, in addition to our publicly released annotation scheme and code, provides solid and practical engineering experience of developing an integrated medical information extraction system.
A Weibo Dataset for the 2022 Russo-Ukrainian Crisis
Mar 09, 2022
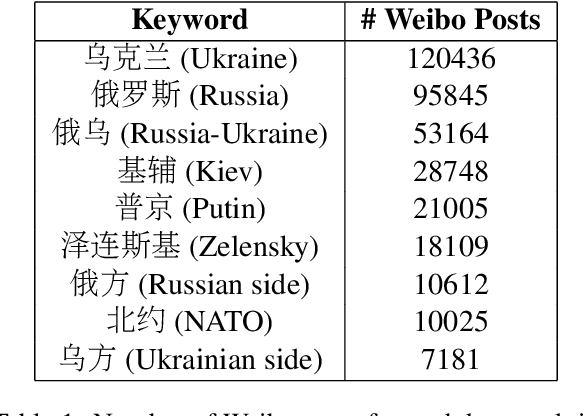
Online social networks such as Twitter and Weibo play an important role in how people stay informed and exchange reactions. Each crisis encompasses a new opportunity to study the portability of models for various tasks (e.g., information extraction, complex event understanding, misinformation detection, etc.), due to differences in domain, entities, and event types. We present the Russia-Ukraine Crisis Weibo (RUW) dataset, with over 3.5M user posts and comments in the first release. Our data is available at https://github.com/yrf1/RussiaUkraine_weibo_dataset.
Semantic Norm Recognition and its application to Portuguese Law
Mar 10, 2022
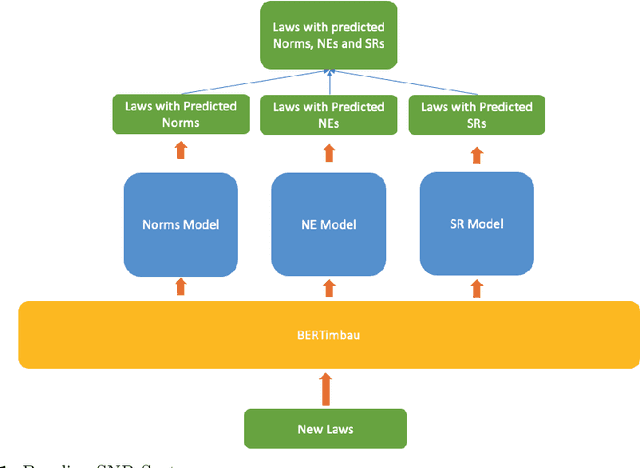
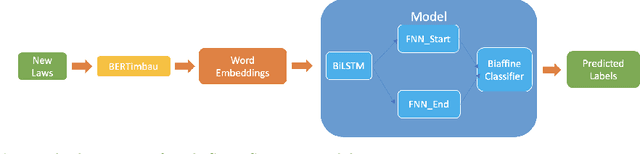

Being able to clearly interpret legal texts and fully understanding our rights, obligations and other legal norms has become progressively more important in the digital society. However, simply giving citizens access to the laws is not enough, as there is a need to provide meaningful information that cater to their specific queries and needs. For this, it is necessary to extract the relevant semantic information present in legal texts. Thus, we introduce the SNR (Semantic Norm Recognition) system, an automatic semantic information extraction system trained on a domain-specific (legal) text corpus taken from Portuguese Consumer Law. The SNR system uses the Portuguese Bert (BERTimbau) and was trained on a legislative Portuguese corpus. We demonstrate how our system achieved good results (81.44\% F1-score) on this domain-specific corpus, despite existing noise, and how it can be used to improve downstream tasks such as information retrieval.
PET: A new Dataset for Process Extraction from Natural Language Text
Mar 09, 2022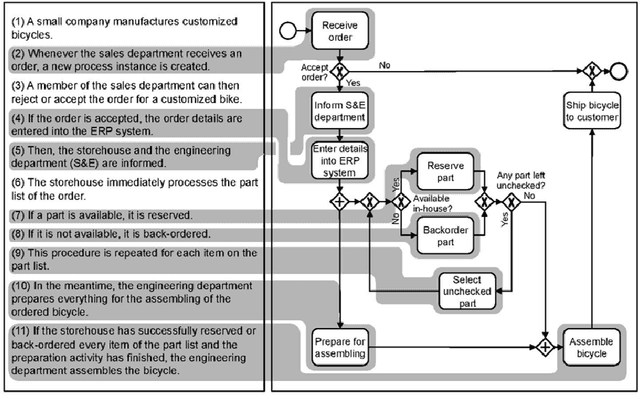
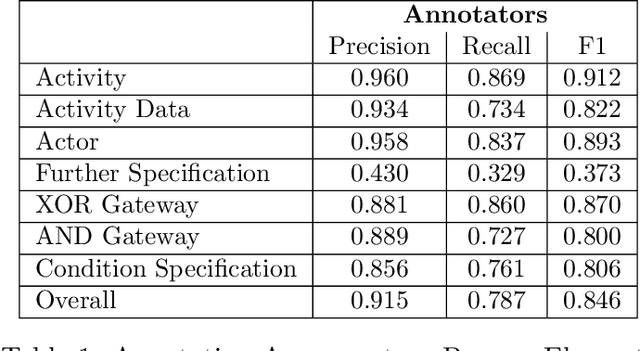
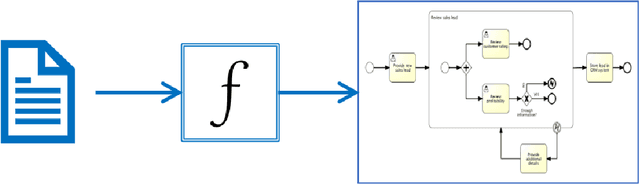
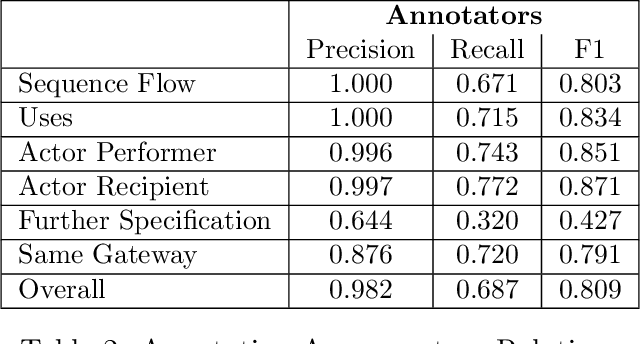
Although there is a long tradition of work in NLP on extracting entities and relations from text, to date there exists little work on the acquisition of business processes from unstructured data such as textual corpora of process descriptions. With this work we aim at filling this gap and establishing the first steps towards bridging data-driven information extraction methodologies from Natural Language Processing and the model-based formalization that is aimed from Business Process Management. For this, we develop the first corpus of business process descriptions annotated with activities, gateways, actors and flow information. We present our new resource, including a detailed overview of the annotation schema and guidelines, as well as a variety of baselines to benchmark the difficulty and challenges of business process extraction from text.
Multi-stage Ensemble Model for Cross-market Recommendation
Feb 17, 2022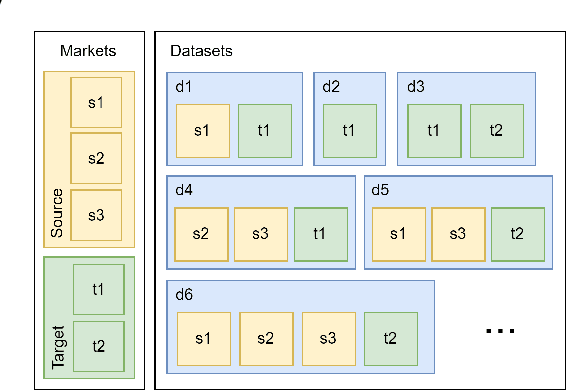
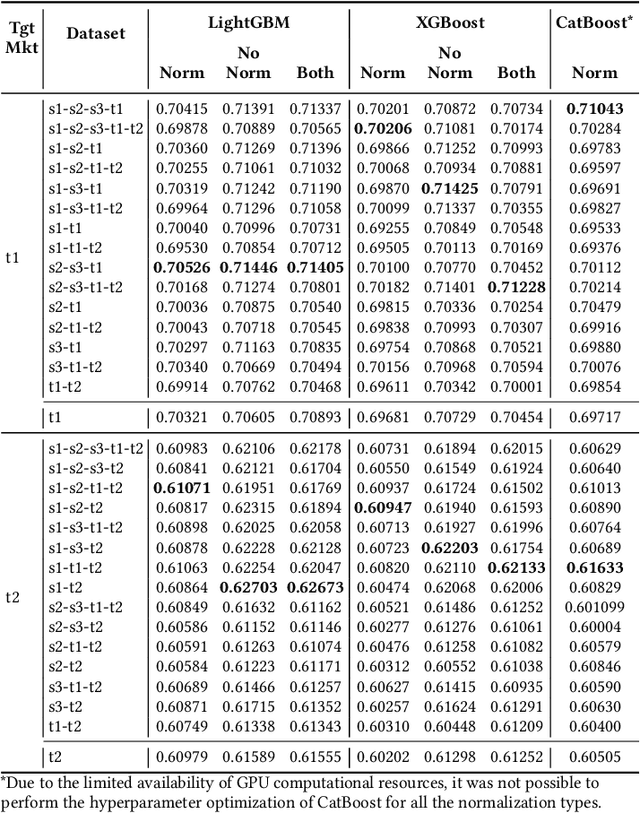
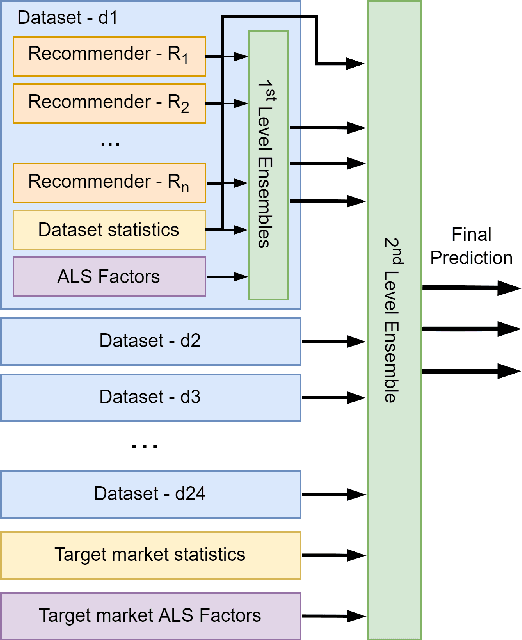
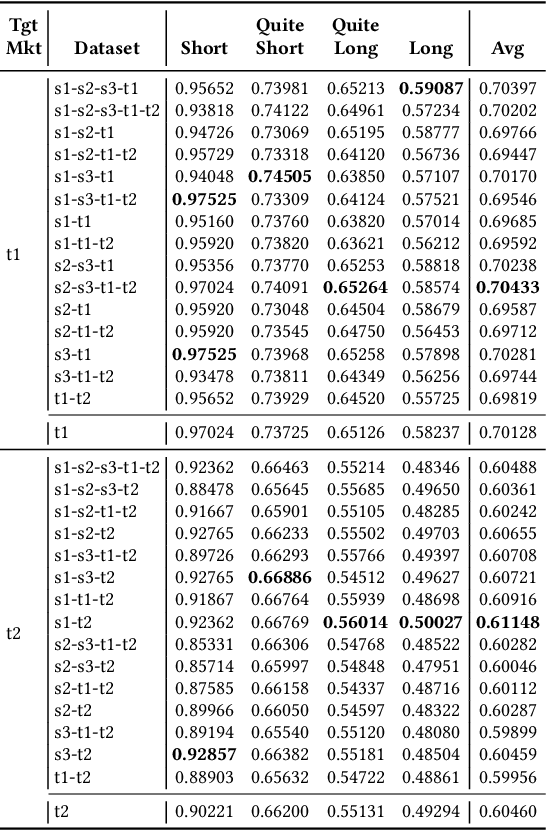
This paper describes the solution of our team PolimiRank for the WSDM Cup 2022 on cross-market recommendation. The goal of the competition is to effectively exploit the information extracted from different markets to improve the ranking accuracy of recommendations on two target markets. Our model consists in a multi-stage approach based on the combination of data belonging to different markets. In the first stage, state-of-the-art recommenders are used to predict scores for user-item couples, which are ensembled in the following 2 stages, employing a simple linear combination and more powerful Gradient Boosting Decision Tree techniques. Our team ranked 4th in the final leaderboard.
Social Network Extraction Unsupervised
Feb 24, 2022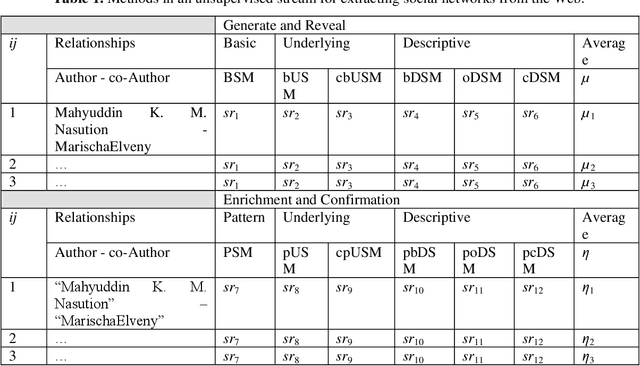
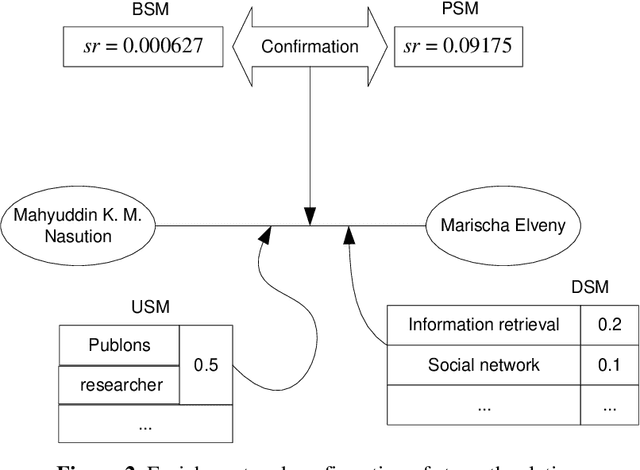
In the era of information technology, the two developing sides are data science and artificial intelligence. In terms of scientific data, one of the tasks is the extraction of social networks from information sources that have the nature of big data. Meanwhile, in terms of artificial intelligence, the presence of contradictory methods has an impact on knowledge. This article describes an unsupervised as a stream of methods for extracting social networks from information sources. There are a variety of possible approaches and strategies to superficial methods as a starting concept. Each method has its advantages, but in general, it contributes to the integration of each other, namely simplifying, enriching, and emphasizing the results.
* 7
Towards the automated large-scale reconstruction of past road networks from historical maps
Feb 11, 2022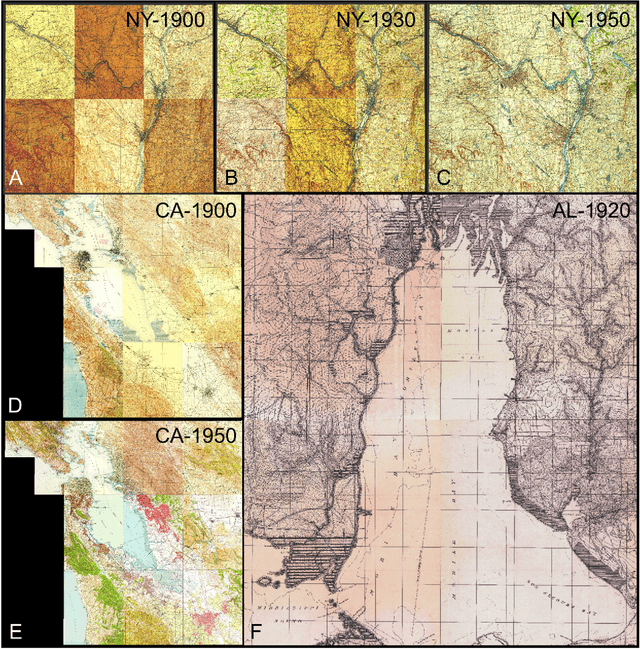

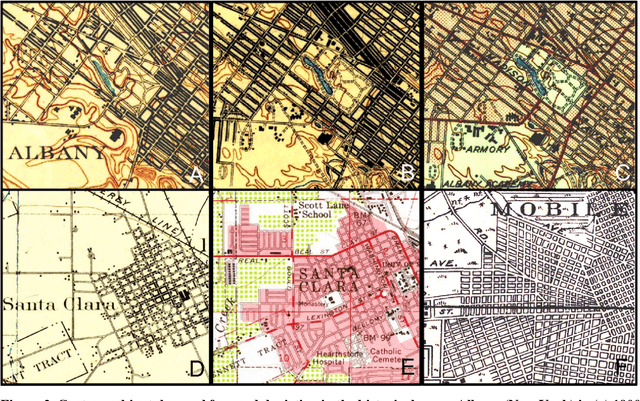

Transportation infrastructure, such as road or railroad networks, represent a fundamental component of our civilization. For sustainable planning and informed decision making, a thorough understanding of the long-term evolution of transportation infrastructure such as road networks is crucial. However, spatially explicit, multi-temporal road network data covering large spatial extents are scarce and rarely available prior to the 2000s. Herein, we propose a framework that employs increasingly available scanned and georeferenced historical map series to reconstruct past road networks, by integrating abundant, contemporary road network data and color information extracted from historical maps. Specifically, our method uses contemporary road segments as analytical units and extracts historical roads by inferring their existence in historical map series based on image processing and clustering techniques. We tested our method on over 300,000 road segments representing more than 50,000 km of the road network in the United States, extending across three study areas that cover 53 historical topographic map sheets dated between 1890 and 1950. We evaluated our approach by comparison to other historical datasets and against manually created reference data, achieving F-1 scores of up to 0.95, and showed that the extracted road network statistics are highly plausible over time, i.e., following general growth patterns. We demonstrated that contemporary geospatial data integrated with information extracted from historical map series open up new avenues for the quantitative analysis of long-term urbanization processes and landscape changes far beyond the era of operational remote sensing and digital cartography.
Adversarial Graph Contrastive Learning with Information Regularization
Mar 03, 2022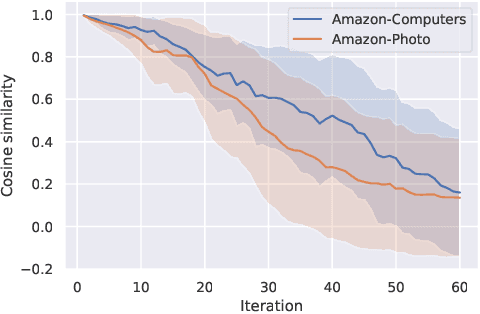
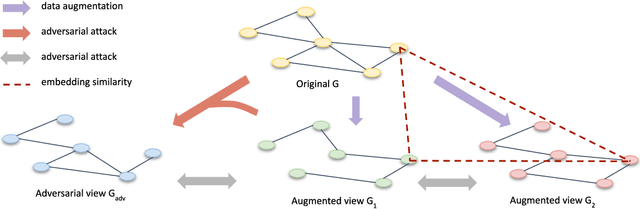
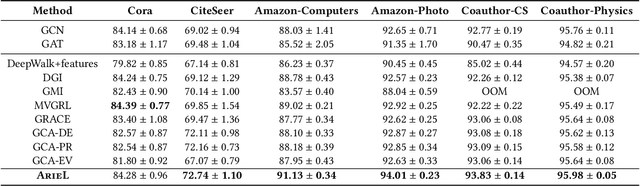
Contrastive learning is an effective unsupervised method in graph representation learning. Recently, the data augmentation based contrastive learning method has been extended from images to graphs. However, most prior works are directly adapted from the models designed for images. Unlike the data augmentation on images, the data augmentation on graphs is far less intuitive and much harder to provide high-quality contrastive samples, which are the key to the performance of contrastive learning models. This leaves much space for improvement over the existing graph contrastive learning frameworks. In this work, by introducing an adversarial graph view and an information regularizer, we propose a simple but effective method, Adversarial Graph Contrastive Learning (ARIEL), to extract informative contrastive samples within a reasonable constraint. It consistently outperforms the current graph contrastive learning methods in the node classification task over various real-world datasets and further improves the robustness of graph contrastive learning.
XAutoML: A Visual Analytics Tool for Establishing Trust in Automated Machine Learning
Feb 24, 2022
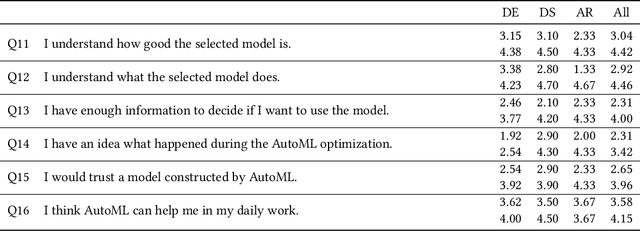
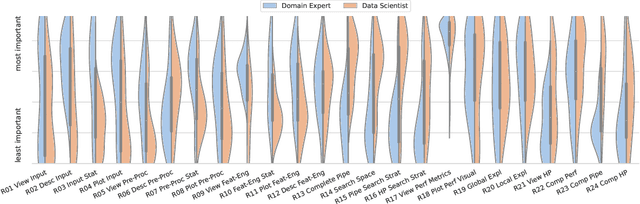

In the last ten years, various automated machine learning (AutoML) systems have been proposed to build end-to-end machine learning (ML) pipelines with minimal human interaction. Even though such automatically synthesized ML pipelines are able to achieve a competitive performance, recent studies have shown that users do not trust models constructed by AutoML due to missing transparency of AutoML systems and missing explanations for the constructed ML pipelines. In a requirements analysis study with 26 domain experts, data scientists, and AutoML researchers from different professions with vastly different expertise in ML, we collect detailed informational needs to establish trust in AutoML. We propose XAutoML, an interactive visual analytics tool for explaining arbitrary AutoML optimization procedures and ML pipelines constructed by AutoML. XAutoML combines interactive visualizations with established techniques from explainable artificial intelligence (XAI) to make the complete AutoML procedure transparent and explainable. By integrating XAutoML with JupyterLab, experienced users can extend the visual analytics with ad-hoc visualizations based on information extracted from XAutoML. We validate our approach in a user study with the same diverse user group from the requirements analysis. All participants were able to extract useful information from XAutoML, leading to a significantly increased trust in ML pipelines produced by AutoML and the AutoML optimization itself.