 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
Language-Driven Active Learning for Diverse Open-Set 3D Object Detection
Apr 19, 2024
Object detection is crucial for ensuring safe autonomous driving. However, data-driven approaches face challenges when encountering minority or novel objects in the 3D driving scene. In this paper, we propose VisLED, a language-driven active learning framework for diverse open-set 3D Object Detection. Our method leverages active learning techniques to query diverse and informative data samples from an unlabeled pool, enhancing the model's ability to detect underrepresented or novel objects. Specifically, we introduce the Vision-Language Embedding Diversity Querying (VisLED-Querying) algorithm, which operates in both open-world exploring and closed-world mining settings. In open-world exploring, VisLED-Querying selects data points most novel relative to existing data, while in closed-world mining, it mines new instances of known classes. We evaluate our approach on the nuScenes dataset and demonstrate its effectiveness compared to random sampling and entropy-querying methods. Our results show that VisLED-Querying consistently outperforms random sampling and offers competitive performance compared to entropy-querying despite the latter's model-optimality, highlighting the potential of VisLED for improving object detection in autonomous driving scenarios.
Detector Collapse: Backdooring Object Detection to Catastrophic Overload or Blindness
Apr 17, 2024Object detection tasks, crucial in safety-critical systems like autonomous driving, focus on pinpointing object locations. These detectors are known to be susceptible to backdoor attacks. However, existing backdoor techniques have primarily been adapted from classification tasks, overlooking deeper vulnerabilities specific to object detection. This paper is dedicated to bridging this gap by introducing Detector Collapse} (DC), a brand-new backdoor attack paradigm tailored for object detection. DC is designed to instantly incapacitate detectors (i.e., severely impairing detector's performance and culminating in a denial-of-service). To this end, we develop two innovative attack schemes: Sponge for triggering widespread misidentifications and Blinding for rendering objects invisible. Remarkably, we introduce a novel poisoning strategy exploiting natural objects, enabling DC to act as a practical backdoor in real-world environments. Our experiments on different detectors across several benchmarks show a significant improvement ($\sim$10\%-60\% absolute and $\sim$2-7$\times$ relative) in attack efficacy over state-of-the-art attacks.
Overcoming Scene Context Constraints for Object Detection in wild using Defilters
Apr 12, 2024This paper focuses on improving object detection performance by addressing the issue of image distortions, commonly encountered in uncontrolled acquisition environments. High-level computer vision tasks such as object detection, recognition, and segmentation are particularly sensitive to image distortion. To address this issue, we propose a novel approach employing an image defilter to rectify image distortion prior to object detection. This method enhances object detection accuracy, as models perform optimally when trained on non-distorted images. Our experiments demonstrate that utilizing defiltered images significantly improves mean average precision compared to training object detection models on distorted images. Consequently, our proposed method offers considerable benefits for real-world applications plagued by image distortion. To our knowledge, the contribution lies in employing distortion-removal paradigm for object detection on images captured in natural settings. We achieved an improvement of 0.562 and 0.564 of mean Average precision on validation and test data.
Feature Corrective Transfer Learning: End-to-End Solutions to Object Detection in Non-Ideal Visual Conditions
Apr 19, 2024A significant challenge in the field of object detection lies in the system's performance under non-ideal imaging conditions, such as rain, fog, low illumination, or raw Bayer images that lack ISP processing. Our study introduces "Feature Corrective Transfer Learning", a novel approach that leverages transfer learning and a bespoke loss function to facilitate the end-to-end detection of objects in these challenging scenarios without the need to convert non-ideal images into their RGB counterparts. In our methodology, we initially train a comprehensive model on a pristine RGB image dataset. Subsequently, non-ideal images are processed by comparing their feature maps against those from the initial ideal RGB model. This comparison employs the Extended Area Novel Structural Discrepancy Loss (EANSDL), a novel loss function designed to quantify similarities and integrate them into the detection loss. This approach refines the model's ability to perform object detection across varying conditions through direct feature map correction, encapsulating the essence of Feature Corrective Transfer Learning. Experimental validation on variants of the KITTI dataset demonstrates a significant improvement in mean Average Precision (mAP), resulting in a 3.8-8.1% relative enhancement in detection under non-ideal conditions compared to the baseline model, and a less marginal performance difference within 1.3% of the mAP@[0.5:0.95] achieved under ideal conditions by the standard Faster RCNN algorithm.
Simple In-place Data Augmentation for Surveillance Object Detection
Apr 17, 2024Motivated by the need to improve model performance in traffic monitoring tasks with limited labeled samples, we propose a straightforward augmentation technique tailored for object detection datasets, specifically designed for stationary camera-based applications. Our approach focuses on placing objects in the same positions as the originals to ensure its effectiveness. By applying in-place augmentation on objects from the same camera input image, we address the challenge of overlapping with original and previously selected objects. Through extensive testing on two traffic monitoring datasets, we illustrate the efficacy of our augmentation strategy in improving model performance, particularly in scenarios with limited labeled samples and imbalanced class distributions. Notably, our method achieves comparable performance to models trained on the entire dataset while utilizing only 8.5 percent of the original data. Moreover, we report significant improvements, with mAP@.5 increasing from 0.4798 to 0.5025, and the mAP@.5:.95 rising from 0.29 to 0.3138 on the FishEye8K dataset. These results highlight the potential of our augmentation approach in enhancing object detection models for traffic monitoring applications.
Coreset Selection for Object Detection
Apr 14, 2024Coreset selection is a method for selecting a small, representative subset of an entire dataset. It has been primarily researched in image classification, assuming there is only one object per image. However, coreset selection for object detection is more challenging as an image can contain multiple objects. As a result, much research has yet to be done on this topic. Therefore, we introduce a new approach, Coreset Selection for Object Detection (CSOD). CSOD generates imagewise and classwise representative feature vectors for multiple objects of the same class within each image. Subsequently, we adopt submodular optimization for considering both representativeness and diversity and utilize the representative vectors in the submodular optimization process to select a subset. When we evaluated CSOD on the Pascal VOC dataset, CSOD outperformed random selection by +6.4%p in AP$_{50}$ when selecting 200 images.
OSR-ViT: A Simple and Modular Framework for Open-Set Object Detection and Discovery
Apr 16, 2024An object detector's ability to detect and flag \textit{novel} objects during open-world deployments is critical for many real-world applications. Unfortunately, much of the work in open object detection today is disjointed and fails to adequately address applications that prioritize unknown object recall \textit{in addition to} known-class accuracy. To close this gap, we present a new task called Open-Set Object Detection and Discovery (OSODD) and as a solution propose the Open-Set Regions with ViT features (OSR-ViT) detection framework. OSR-ViT combines a class-agnostic proposal network with a powerful ViT-based classifier. Its modular design simplifies optimization and allows users to easily swap proposal solutions and feature extractors to best suit their application. Using our multifaceted evaluation protocol, we show that OSR-ViT obtains performance levels that far exceed state-of-the-art supervised methods. Our method also excels in low-data settings, outperforming supervised baselines using a fraction of the training data.
Multimodal 3D Object Detection on Unseen Domains
Apr 17, 2024LiDAR datasets for autonomous driving exhibit biases in properties such as point cloud density, range, and object dimensions. As a result, object detection networks trained and evaluated in different environments often experience performance degradation. Domain adaptation approaches assume access to unannotated samples from the test distribution to address this problem. However, in the real world, the exact conditions of deployment and access to samples representative of the test dataset may be unavailable while training. We argue that the more realistic and challenging formulation is to require robustness in performance to unseen target domains. We propose to address this problem in a two-pronged manner. First, we leverage paired LiDAR-image data present in most autonomous driving datasets to perform multimodal object detection. We suggest that working with multimodal features by leveraging both images and LiDAR point clouds for scene understanding tasks results in object detectors more robust to unseen domain shifts. Second, we train a 3D object detector to learn multimodal object features across different distributions and promote feature invariance across these source domains to improve generalizability to unseen target domains. To this end, we propose CLIX$^\text{3D}$, a multimodal fusion and supervised contrastive learning framework for 3D object detection that performs alignment of object features from same-class samples of different domains while pushing the features from different classes apart. We show that CLIX$^\text{3D}$ yields state-of-the-art domain generalization performance under multiple dataset shifts.
Run-time Monitoring of 3D Object Detection in Automated Driving Systems Using Early Layer Neural Activation Patterns
Apr 11, 2024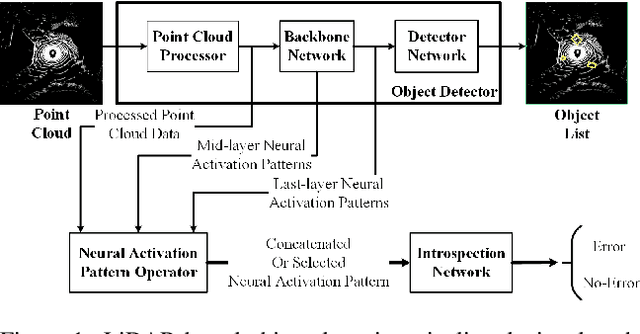
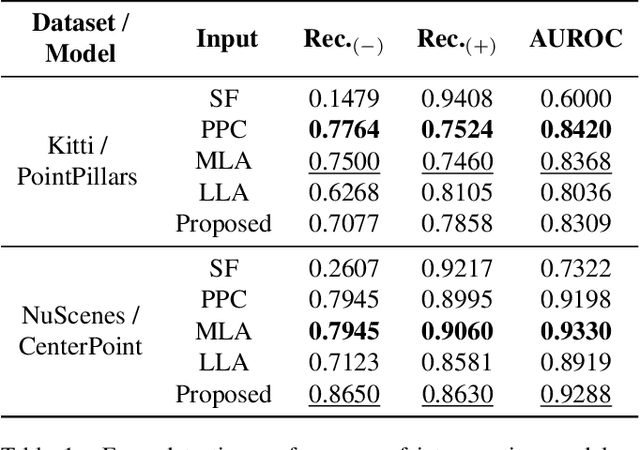
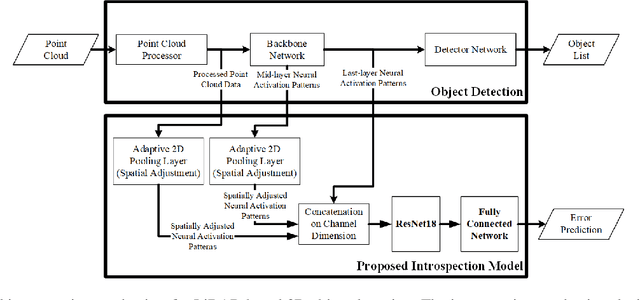
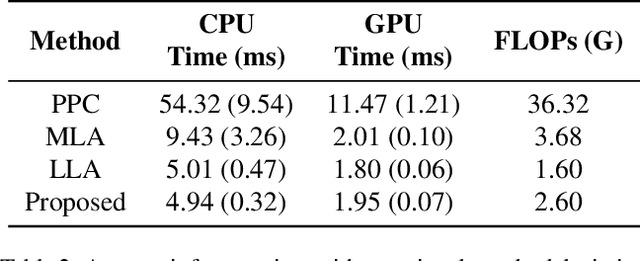
Monitoring the integrity of object detection for errors within the perception module of automated driving systems (ADS) is paramount for ensuring safety. Despite recent advancements in deep neural network (DNN)-based object detectors, their susceptibility to detection errors, particularly in the less-explored realm of 3D object detection, remains a significant concern. State-of-the-art integrity monitoring (also known as introspection) mechanisms in 2D object detection mainly utilise the activation patterns in the final layer of the DNN-based detector's backbone. However, that may not sufficiently address the complexities and sparsity of data in 3D object detection. To this end, we conduct, in this article, an extensive investigation into the effects of activation patterns extracted from various layers of the backbone network for introspecting the operation of 3D object detectors. Through a comparative analysis using Kitti and NuScenes datasets with PointPillars and CenterPoint detectors, we demonstrate that using earlier layers' activation patterns enhances the error detection performance of the integrity monitoring system, yet increases computational complexity. To address the real-time operation requirements in ADS, we also introduce a novel introspection method that combines activation patterns from multiple layers of the detector's backbone and report its performance.
Multi-resolution Rescored ByteTrack for Video Object Detection on Ultra-low-power Embedded Systems
Apr 17, 2024This paper introduces Multi-Resolution Rescored Byte-Track (MR2-ByteTrack), a novel video object detection framework for ultra-low-power embedded processors. This method reduces the average compute load of an off-the-shelf Deep Neural Network (DNN) based object detector by up to 2.25$\times$ by alternating the processing of high-resolution images (320$\times$320 pixels) with multiple down-sized frames (192$\times$192 pixels). To tackle the accuracy degradation due to the reduced image input size, MR2-ByteTrack correlates the output detections over time using the ByteTrack tracker and corrects potential misclassification using a novel probabilistic Rescore algorithm. By interleaving two down-sized images for every high-resolution one as the input of different state-of-the-art DNN object detectors with our MR2-ByteTrack, we demonstrate an average accuracy increase of 2.16% and a latency reduction of 43% on the GAP9 microcontroller compared to a baseline frame-by-frame inference scheme using exclusively full-resolution images. Code available at: https://github.com/Bomps4/Multi_Resolution_Rescored_ByteTrack