 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
When LLMs are Unfit Use FastFit: Fast and Effective Text Classification with Many Classes
Apr 18, 2024
We present FastFit, a method, and a Python package design to provide fast and accurate few-shot classification, especially for scenarios with many semantically similar classes. FastFit utilizes a novel approach integrating batch contrastive learning and token-level similarity score. Compared to existing few-shot learning packages, such as SetFit, Transformers, or few-shot prompting of large language models via API calls, FastFit significantly improves multiclass classification performance in speed and accuracy across FewMany, our newly curated English benchmark, and Multilingual datasets. FastFit demonstrates a 3-20x improvement in training speed, completing training in just a few seconds. The FastFit package is now available on GitHub and PyPi, presenting a user-friendly solution for NLP practitioners.
Small Language Models are Good Too: An Empirical Study of Zero-Shot Classification
Apr 17, 2024This study is part of the debate on the efficiency of large versus small language models for text classification by prompting.We assess the performance of small language models in zero-shot text classification, challenging the prevailing dominance of large models.Across 15 datasets, our investigation benchmarks language models from 77M to 40B parameters using different architectures and scoring functions. Our findings reveal that small models can effectively classify texts, getting on par with or surpassing their larger counterparts.We developed and shared a comprehensive open-source repository that encapsulates our methodologies. This research underscores the notion that bigger isn't always better, suggesting that resource-efficient small models may offer viable solutions for specific data classification challenges.
Ukrainian Texts Classification: Exploration of Cross-lingual Knowledge Transfer Approaches
Apr 02, 2024Despite the extensive amount of labeled datasets in the NLP text classification field, the persistent imbalance in data availability across various languages remains evident. Ukrainian, in particular, stands as a language that still can benefit from the continued refinement of cross-lingual methodologies. Due to our knowledge, there is a tremendous lack of Ukrainian corpora for typical text classification tasks. In this work, we leverage the state-of-the-art advances in NLP, exploring cross-lingual knowledge transfer methods avoiding manual data curation: large multilingual encoders and translation systems, LLMs, and language adapters. We test the approaches on three text classification tasks -- toxicity classification, formality classification, and natural language inference -- providing the "recipe" for the optimal setups.
AI-Enhanced Cognitive Behavioral Therapy: Deep Learning and Large Language Models for Extracting Cognitive Pathways from Social Media Texts
Apr 17, 2024Cognitive Behavioral Therapy (CBT) is an effective technique for addressing the irrational thoughts stemming from mental illnesses, but it necessitates precise identification of cognitive pathways to be successfully implemented in patient care. In current society, individuals frequently express negative emotions on social media on specific topics, often exhibiting cognitive distortions, including suicidal behaviors in extreme cases. Yet, there is a notable absence of methodologies for analyzing cognitive pathways that could aid psychotherapists in conducting effective interventions online. In this study, we gathered data from social media and established the task of extracting cognitive pathways, annotating the data based on a cognitive theoretical framework. We initially categorized the task of extracting cognitive pathways as a hierarchical text classification with four main categories and nineteen subcategories. Following this, we structured a text summarization task to help psychotherapists quickly grasp the essential information. Our experiments evaluate the performance of deep learning and large language models (LLMs) on these tasks. The results demonstrate that our deep learning method achieved a micro-F1 score of 62.34% in the hierarchical text classification task. Meanwhile, in the text summarization task, GPT-4 attained a Rouge-1 score of 54.92 and a Rouge-2 score of 30.86, surpassing the experimental deep learning model's performance. However, it may suffer from an issue of hallucination. We have made all models and codes publicly available to support further research in this field.
Transformer-Based Classification Outcome Prediction for Multimodal Stroke Treatment
Apr 19, 2024This study proposes a multi-modal fusion framework Multitrans based on the Transformer architecture and self-attention mechanism. This architecture combines the study of non-contrast computed tomography (NCCT) images and discharge diagnosis reports of patients undergoing stroke treatment, using a variety of methods based on Transformer architecture approach to predicting functional outcomes of stroke treatment. The results show that the performance of single-modal text classification is significantly better than single-modal image classification, but the effect of multi-modal combination is better than any single modality. Although the Transformer model only performs worse on imaging data, when combined with clinical meta-diagnostic information, both can learn better complementary information and make good contributions to accurately predicting stroke treatment effects..
A Novel ICD Coding Framework Based on Associated and Hierarchical Code Description Distillation
Apr 17, 2024ICD(International Classification of Diseases) coding involves assigning ICD codes to patients visit based on their medical notes. ICD coding is a challenging multilabel text classification problem due to noisy medical document inputs. Recent advancements in automated ICD coding have enhanced performance by integrating additional data and knowledge bases with the encoding of medical notes and codes. However, most of them ignore the code hierarchy, leading to improper code assignments. To address these problems, we propose a novel framework based on associated and hierarchical code description distillation (AHDD) for better code representation learning and avoidance of improper code assignment.we utilize the code description and the hierarchical structure inherent to the ICD codes. Therefore, in this paper, we leverage the code description and the hierarchical structure inherent to the ICD codes. The code description is also applied to aware the attention layer and output layer. Experimental results on the benchmark dataset show the superiority of the proposed framework over several state-of-the-art baselines.
Incubating Text Classifiers Following User Instruction with Nothing but LLM
Apr 16, 2024In this paper, we aim to generate text classification data given arbitrary class definitions (i.e., user instruction), so one can train a small text classifier without any human annotation or raw corpus. Compared with pioneer attempts, our proposed Incubator is the first framework that can handle complicated and even mutually dependent classes (e.g., "TED Talk given by Educator" and "Other"). Specifically, Incubator is an LLM firstly tuned on the instruction-to-data mappings that we obtained from classification datasets and descriptions on HuggingFace together with in-context augmentation by GPT-4. We then refine Incubator by learning on the cluster centers of semantic textual embeddings to emphasize the uniformity and semantic diversity in generations. We compare Incubator on various classification tasks with strong baselines such as direct LLM-based inference and training data generation by prompt engineering. Experiments show Incubator is able to (1) perform well on traditional benchmarks, (2) take label dependency and user preference into consideration, and (3) enable logical text mining by incubating multiple classifiers.
Enhancing Low-Resource LLMs Classification with PEFT and Synthetic Data
Apr 03, 2024Large Language Models (LLMs) operating in 0-shot or few-shot settings achieve competitive results in Text Classification tasks. In-Context Learning (ICL) typically achieves better accuracy than the 0-shot setting, but it pays in terms of efficiency, due to the longer input prompt. In this paper, we propose a strategy to make LLMs as efficient as 0-shot text classifiers, while getting comparable or better accuracy than ICL. Our solution targets the low resource setting, i.e., when only 4 examples per class are available. Using a single LLM and few-shot real data we perform a sequence of generation, filtering and Parameter-Efficient Fine-Tuning steps to create a robust and efficient classifier. Experimental results show that our approach leads to competitive results on multiple text classification datasets.
Comprehensive Implementation of TextCNN for Enhanced Collaboration between Natural Language Processing and System Recommendation
Mar 12, 2024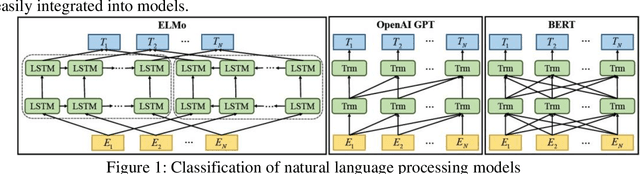
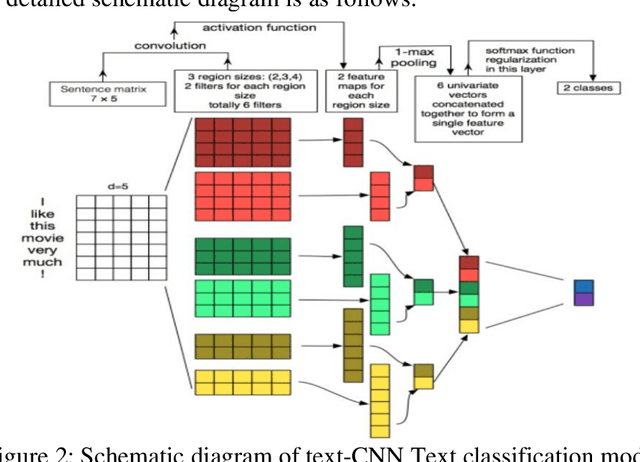
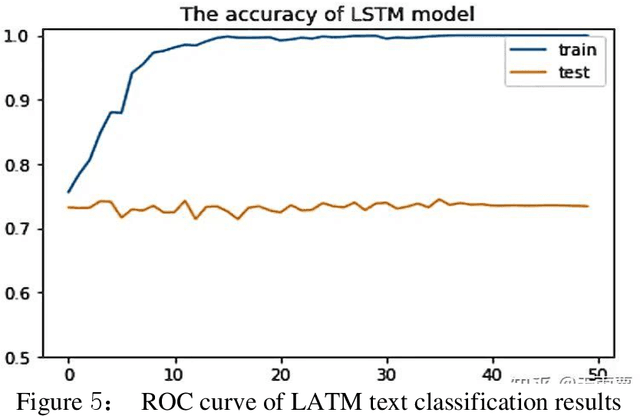
Natural Language Processing (NLP) is an important branch of artificial intelligence that studies how to enable computers to understand, process, and generate human language. Text classification is a fundamental task in NLP, which aims to classify text into different predefined categories. Text classification is the most basic and classic task in natural language processing, and most of the tasks in natural language processing can be regarded as classification tasks. In recent years, deep learning has achieved great success in many research fields, and today, it has also become a standard technology in the field of NLP, which is widely integrated into text classification tasks. Unlike numbers and images, text processing emphasizes fine-grained processing ability. Traditional text classification methods generally require preprocessing the input model's text data. Additionally, they also need to obtain good sample features through manual annotation and then use classical machine learning algorithms for classification. Therefore, this paper analyzes the application status of deep learning in the three core tasks of NLP (including text representation, word order modeling, and knowledge representation). This content explores the improvement and synergy achieved through natural language processing in the context of text classification, while also taking into account the challenges posed by adversarial techniques in text generation, text classification, and semantic parsing. An empirical study on text classification tasks demonstrates the effectiveness of interactive integration training, particularly in conjunction with TextCNN, highlighting the significance of these advancements in text classification augmentation and enhancement.
OTTER: Improving Zero-Shot Classification via Optimal Transport
Apr 12, 2024Popular zero-shot models suffer due to artifacts inherited from pretraining. A particularly detrimental artifact, caused by unbalanced web-scale pretraining data, is mismatched label distribution. Existing approaches that seek to repair the label distribution are not suitable in zero-shot settings, as they have incompatible requirements such as access to labeled downstream task data or knowledge of the true label balance in the pretraining distribution. We sidestep these challenges and introduce a simple and lightweight approach to adjust pretrained model predictions via optimal transport. Our technique requires only an estimate of the label distribution of a downstream task. Theoretically, we characterize the improvement produced by our procedure under certain mild conditions and provide bounds on the error caused by misspecification. Empirically, we validate our method in a wide array of zero-shot image and text classification tasks, improving accuracy by 4.8% and 15.9% on average, and beating baselines like Prior Matching -- often by significant margins -- in 17 out of 21 datasets.