 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRui Liu
Enhanced Detection Classification via Clustering SVM for Various Robot Collaboration Task
May 05, 2024
We introduce an advanced, swift pattern recognition strategy for various multiple robotics during curve negotiation. This method, leveraging a sophisticated k-means clustering-enhanced Support Vector Machine algorithm, distinctly categorizes robotics into flying or mobile robots. Initially, the paradigm considers robot locations and features as quintessential parameters indicative of divergent robot patterns. Subsequently, employing the k-means clustering technique facilitates the efficient segregation and consolidation of robotic data, significantly optimizing the support vector delineation process and expediting the recognition phase. Following this preparatory phase, the SVM methodology is adeptly applied to construct a discriminative hyperplane, enabling precise classification and prognostication of the robot category. To substantiate the efficacy and superiority of the k-means framework over traditional SVM approaches, a rigorous cross-validation experiment was orchestrated, evidencing the former's enhanced performance in robot group classification.
MER 2024: Semi-Supervised Learning, Noise Robustness, and Open-Vocabulary Multimodal Emotion Recognition
Apr 29, 2024



Multimodal emotion recognition is an important research topic in artificial intelligence. Over the past few decades, researchers have made remarkable progress by increasing dataset size and building more effective architectures. However, due to various reasons (such as complex environments and inaccurate labels), current systems still cannot meet the demands of practical applications. Therefore, we plan to organize a series of challenges around emotion recognition to further promote the development of this field. Last year, we launched MER2023, focusing on three topics: multi-label learning, noise robustness, and semi-supervised learning. This year, we continue to organize MER2024. In addition to expanding the dataset size, we introduce a new track around open-vocabulary emotion recognition. The main consideration for this track is that existing datasets often fix the label space and use majority voting to enhance annotator consistency, but this process may limit the model's ability to describe subtle emotions. In this track, we encourage participants to generate any number of labels in any category, aiming to describe the emotional state as accurately as possible. Our baseline is based on MERTools and the code is available at: https://github.com/zeroQiaoba/MERTools/tree/master/MER2024.
EEG-Deformer: A Dense Convolutional Transformer for Brain-computer Interfaces
Apr 25, 2024Effectively learning the temporal dynamics in electroencephalogram (EEG) signals is challenging yet essential for decoding brain activities using brain-computer interfaces (BCIs). Although Transformers are popular for their long-term sequential learning ability in the BCI field, most methods combining Transformers with convolutional neural networks (CNNs) fail to capture the coarse-to-fine temporal dynamics of EEG signals. To overcome this limitation, we introduce EEG-Deformer, which incorporates two main novel components into a CNN-Transformer: (1) a Hierarchical Coarse-to-Fine Transformer (HCT) block that integrates a Fine-grained Temporal Learning (FTL) branch into Transformers, effectively discerning coarse-to-fine temporal patterns; and (2) a Dense Information Purification (DIP) module, which utilizes multi-level, purified temporal information to enhance decoding accuracy. Comprehensive experiments on three representative cognitive tasks consistently verify the generalizability of our proposed EEG-Deformer, demonstrating that it either outperforms existing state-of-the-art methods or is comparable to them. Visualization results show that EEG-Deformer learns from neurophysiologically meaningful brain regions for the corresponding cognitive tasks. The source code can be found at https://github.com/yi-ding-cs/EEG-Deformer.
Infrared Small Target Detection with Scale and Location Sensitivity
Mar 28, 2024



Recently, infrared small target detection (IRSTD) has been dominated by deep-learning-based methods. However, these methods mainly focus on the design of complex model structures to extract discriminative features, leaving the loss functions for IRSTD under-explored. For example, the widely used Intersection over Union (IoU) and Dice losses lack sensitivity to the scales and locations of targets, limiting the detection performance of detectors. In this paper, we focus on boosting detection performance with a more effective loss but a simpler model structure. Specifically, we first propose a novel Scale and Location Sensitive (SLS) loss to handle the limitations of existing losses: 1) for scale sensitivity, we compute a weight for the IoU loss based on target scales to help the detector distinguish targets with different scales: 2) for location sensitivity, we introduce a penalty term based on the center points of targets to help the detector localize targets more precisely. Then, we design a simple Multi-Scale Head to the plain U-Net (MSHNet). By applying SLS loss to each scale of the predictions, our MSHNet outperforms existing state-of-the-art methods by a large margin. In addition, the detection performance of existing detectors can be further improved when trained with our SLS loss, demonstrating the effectiveness and generalization of our SLS loss. The code is available at https://github.com/ying-fu/MSHNet.
Volumetric Environment Representation for Vision-Language Navigation
Mar 21, 2024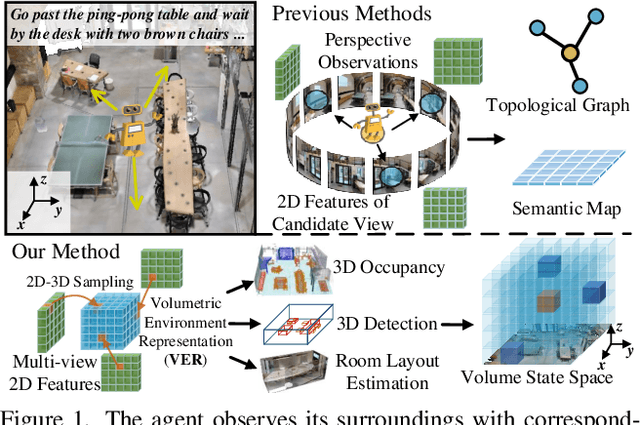
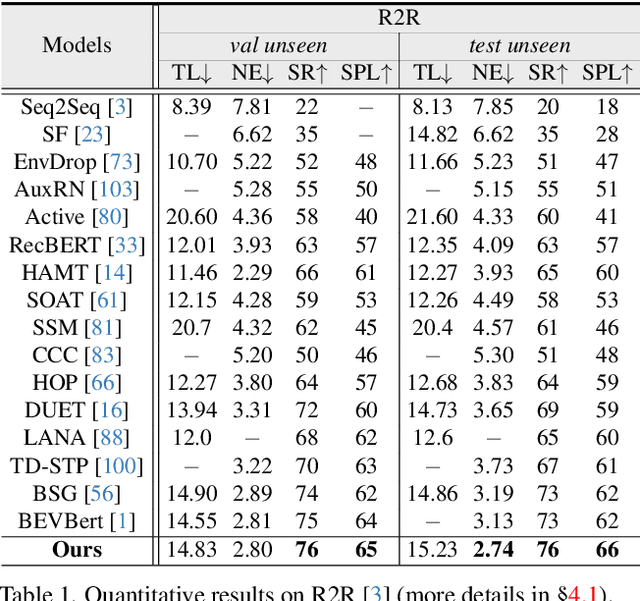
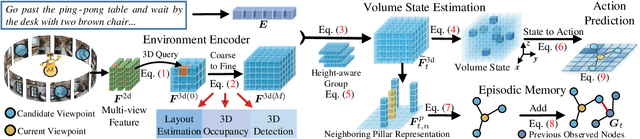
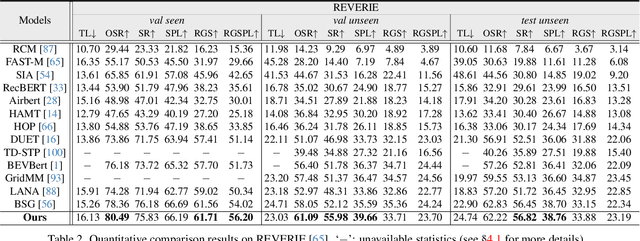
Vision-language navigation (VLN) requires an agent to navigate through an 3D environment based on visual observations and natural language instructions. It is clear that the pivotal factor for successful navigation lies in the comprehensive scene understanding. Previous VLN agents employ monocular frameworks to extract 2D features of perspective views directly. Though straightforward, they struggle for capturing 3D geometry and semantics, leading to a partial and incomplete environment representation. To achieve a comprehensive 3D representation with fine-grained details, we introduce a Volumetric Environment Representation (VER), which voxelizes the physical world into structured 3D cells. For each cell, VER aggregates multi-view 2D features into such a unified 3D space via 2D-3D sampling. Through coarse-to-fine feature extraction and multi-task learning for VER, our agent predicts 3D occupancy, 3D room layout, and 3D bounding boxes jointly. Based on online collected VERs, our agent performs volume state estimation and builds episodic memory for predicting the next step. Experimental results show our environment representations from multi-task learning lead to evident performance gains on VLN. Our model achieves state-of-the-art performance across VLN benchmarks (R2R, REVERIE, and R4R).
LAVA: Long-horizon Visual Action based Food Acquisition
Mar 19, 2024



Robotic Assisted Feeding (RAF) addresses the fundamental need for individuals with mobility impairments to regain autonomy in feeding themselves. The goal of RAF is to use a robot arm to acquire and transfer food to individuals from the table. Existing RAF methods primarily focus on solid foods, leaving a gap in manipulation strategies for semi-solid and deformable foods. This study introduces Long-horizon Visual Action (LAVA) based food acquisition of liquid, semisolid, and deformable foods. Long-horizon refers to the goal of "clearing the bowl" by sequentially acquiring the food from the bowl. LAVA employs a hierarchical policy for long-horizon food acquisition tasks. The framework uses high-level policy to determine primitives by leveraging ScoopNet. At the mid-level, LAVA finds parameters for primitives using vision. To carry out sequential plans in the real world, LAVA delegates action execution which is driven by Low-level policy that uses parameters received from mid-level policy and behavior cloning ensuring precise trajectory execution. We validate our approach on complex real-world acquisition trials involving granular, liquid, semisolid, and deformable food types along with fruit chunks and soup acquisition. Across 46 bowls, LAVA acquires much more efficiently than baselines with a success rate of 89 +/- 4% and generalizes across realistic plate variations such as different positions, varieties, and amount of food in the bowl. Code, datasets, videos, and supplementary materials can be found on our website.
Adaptive Visual Imitation Learning for Robotic Assisted Feeding Across Varied Bowl Configurations and Food Types
Mar 19, 2024



In this study, we introduce a novel visual imitation network with a spatial attention module for robotic assisted feeding (RAF). The goal is to acquire (i.e., scoop) food items from a bowl. However, achieving robust and adaptive food manipulation is particularly challenging. To deal with this, we propose a framework that integrates visual perception with imitation learning to enable the robot to handle diverse scenarios during scooping. Our approach, named AVIL (adaptive visual imitation learning), exhibits adaptability and robustness across different bowl configurations in terms of material, size, and position, as well as diverse food types including granular, semi-solid, and liquid, even in the presence of distractors. We validate the effectiveness of our approach by conducting experiments on a real robot. We also compare its performance with a baseline. The results demonstrate improvement over the baseline across all scenarios, with an enhancement of up to 2.5 times in terms of a success metric. Notably, our model, trained solely on data from a transparent glass bowl containing granular cereals, showcases generalization ability when tested zero-shot on other bowl configurations with different types of food.
Towards Efficient Risk-Sensitive Policy Gradient: An Iteration Complexity Analysis
Mar 13, 2024



Reinforcement Learning (RL) has shown exceptional performance across various applications, enabling autonomous agents to learn optimal policies through interaction with their environments. However, traditional RL frameworks often face challenges in terms of iteration complexity and robustness. Risk-sensitive RL, which balances expected return and risk, has been explored for its potential to yield probabilistically robust policies, yet its iteration complexity analysis remains underexplored. In this study, we conduct a thorough iteration complexity analysis for the risk-sensitive policy gradient method, focusing on the REINFORCE algorithm and employing the exponential utility function. We obtain an iteration complexity of $\mathcal{O}(\epsilon^{-2})$ to reach an $\epsilon$-approximate first-order stationary point (FOSP). We investigate whether risk-sensitive algorithms can achieve better iteration complexity compared to their risk-neutral counterparts. Our theoretical analysis demonstrates that risk-sensitive REINFORCE can have a reduced number of iterations required for convergence. This leads to improved iteration complexity, as employing the exponential utility does not entail additional computation per iteration. We characterize the conditions under which risk-sensitive algorithms can achieve better iteration complexity. Our simulation results also validate that risk-averse cases can converge and stabilize more quickly after approximately half of the episodes compared to their risk-neutral counterparts.
Federated Joint Learning of Robot Networks in Stroke Rehabilitation
Mar 08, 2024



Advanced by rich perception and precise execution, robots possess immense potential to provide professional and customized rehabilitation exercises for patients with mobility impairments caused by strokes. Autonomous robotic rehabilitation significantly reduces human workloads in the long and tedious rehabilitation process. However, training a rehabilitation robot is challenging due to the data scarcity issue. This challenge arises from privacy concerns (e.g., the risk of leaking private disease and identity information of patients) during clinical data access and usage. Data from various patients and hospitals cannot be shared for adequate robot training, further compromising rehabilitation safety and limiting implementation scopes. To address this challenge, this work developed a novel federated joint learning (FJL) method to jointly train robots across hospitals. FJL also adopted a long short-term memory network (LSTM)-Transformer learning mechanism to effectively explore the complex tempo-spatial relations among patient mobility conditions and robotic rehabilitation motions. To validate FJL's effectiveness in training a robot network, a clinic-simulation combined experiment was designed. Real rehabilitation exercise data from 200 patients with stroke diseases (upper limb hemiplegia, Parkinson's syndrome, and back pain syndrome) were adopted. Inversely driven by clinical data, 300,000 robotic rehabilitation guidances were simulated. FJL proved to be effective in joint rehabilitation learning, performing 20% - 30% better than baseline methods.
HGIC: A Hand Gesture Based Interactive Control System for Efficient and Scalable Multi-UAV Operations
Mar 08, 2024



As technological advancements continue to expand the capabilities of multi unmanned-aerial-vehicle systems (mUAV), human operators face challenges in scalability and efficiency due to the complex cognitive load and operations associated with motion adjustments and team coordination. Such cognitive demands limit the feasible size of mUAV teams and necessitate extensive operator training, impeding broader adoption. This paper developed a Hand Gesture Based Interactive Control (HGIC), a novel interface system that utilize computer vision techniques to intuitively translate hand gestures into modular commands for robot teaming. Through learning control models, these commands enable efficient and scalable mUAV motion control and adjustments. HGIC eliminates the need for specialized hardware and offers two key benefits: 1) Minimal training requirements through natural gestures; and 2) Enhanced scalability and efficiency via adaptable commands. By reducing the cognitive burden on operators, HGIC opens the door for more effective large-scale mUAV applications in complex, dynamic, and uncertain scenarios. HGIC will be open-sourced after the paper being published online for the research community, aiming to drive forward innovations in human-mUAV interactions.