 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhi Liu
WiOpen: A Robust Wi-Fi-based Open-set Gesture Recognition Framework
Feb 01, 2024
Recent years have witnessed a growing interest in Wi-Fi-based gesture recognition. However, existing works have predominantly focused on closed-set paradigms, where all testing gestures are predefined during training. This poses a significant challenge in real-world applications, as unseen gestures might be misclassified as known classes during testing. To address this issue, we propose WiOpen, a robust Wi-Fi-based Open-Set Gesture Recognition (OSGR) framework. Implementing OSGR requires addressing challenges caused by the unique uncertainty in Wi-Fi sensing. This uncertainty, resulting from noise and domains, leads to widely scattered and irregular data distributions in collected Wi-Fi sensing data. Consequently, data ambiguity between classes and challenges in defining appropriate decision boundaries to identify unknowns arise. To tackle these challenges, WiOpen adopts a two-fold approach to eliminate uncertainty and define precise decision boundaries. Initially, it addresses uncertainty induced by noise during data preprocessing by utilizing the CSI ratio. Next, it designs the OSGR network based on an uncertainty quantification method. Throughout the learning process, this network effectively mitigates uncertainty stemming from domains. Ultimately, the network leverages relationships among samples' neighbors to dynamically define open-set decision boundaries, successfully realizing OSGR. Comprehensive experiments on publicly accessible datasets confirm WiOpen's effectiveness. Notably, WiOpen also demonstrates superiority in cross-domain tasks when compared to state-of-the-art approaches.
Context-Aware Interaction Network for RGB-T Semantic Segmentation
Jan 03, 2024RGB-T semantic segmentation is a key technique for autonomous driving scenes understanding. For the existing RGB-T semantic segmentation methods, however, the effective exploration of the complementary relationship between different modalities is not implemented in the information interaction between multiple levels. To address such an issue, the Context-Aware Interaction Network (CAINet) is proposed for RGB-T semantic segmentation, which constructs interaction space to exploit auxiliary tasks and global context for explicitly guided learning. Specifically, we propose a Context-Aware Complementary Reasoning (CACR) module aimed at establishing the complementary relationship between multimodal features with the long-term context in both spatial and channel dimensions. Further, considering the importance of global contextual and detailed information, we propose the Global Context Modeling (GCM) module and Detail Aggregation (DA) module, and we introduce specific auxiliary supervision to explicitly guide the context interaction and refine the segmentation map. Extensive experiments on two benchmark datasets of MFNet and PST900 demonstrate that the proposed CAINet achieves state-of-the-art performance. The code is available at https://github.com/YingLv1106/CAINet.
Texture-Semantic Collaboration Network for ORSI Salient Object Detection
Dec 06, 2023Salient object detection (SOD) in optical remote sensing images (ORSIs) has become increasingly popular recently. Due to the characteristics of ORSIs, ORSI-SOD is full of challenges, such as multiple objects, small objects, low illuminations, and irregular shapes. To address these challenges, we propose a concise yet effective Texture-Semantic Collaboration Network (TSCNet) to explore the collaboration of texture cues and semantic cues for ORSI-SOD. Specifically, TSCNet is based on the generic encoder-decoder structure. In addition to the encoder and decoder, TSCNet includes a vital Texture-Semantic Collaboration Module (TSCM), which performs valuable feature modulation and interaction on basic features extracted from the encoder. The main idea of our TSCM is to make full use of the texture features at the lowest level and the semantic features at the highest level to achieve the expression enhancement of salient regions on features. In the TSCM, we first enhance the position of potential salient regions using semantic features. Then, we render and restore the object details using the texture features. Meanwhile, we also perceive regions of various scales, and construct interactions between different regions. Thanks to the perfect combination of TSCM and generic structure, our TSCNet can take care of both the position and details of salient objects, effectively handling various scenes. Extensive experiments on three datasets demonstrate that our TSCNet achieves competitive performance compared to 14 state-of-the-art methods. The code and results of our method are available at https://github.com/MathLee/TSCNet.
Viewport Prediction for Volumetric Video Streaming by Exploring Video Saliency and Trajectory Information
Nov 28, 2023Volumetric video, also known as hologram video, is a novel medium that portrays natural content in Virtual Reality (VR), Augmented Reality (AR), and Mixed Reality (MR). It is expected to be the next-gen video technology and a prevalent use case for 5G and beyond wireless communication. Considering that each user typically only watches a section of the volumetric video, known as the viewport, it is essential to have precise viewport prediction for optimal performance. However, research on this topic is still in its infancy. In the end, this paper presents and proposes a novel approach, named Saliency and Trajectory Viewport Prediction (STVP), which aims to improve the precision of viewport prediction in volumetric video streaming. The STVP extensively utilizes video saliency information and viewport trajectory. To our knowledge, this is the first comprehensive study of viewport prediction in volumetric video streaming. In particular, we introduce a novel sampling method, Uniform Random Sampling (URS), to reduce computational complexity while still preserving video features in an efficient manner. Then we present a saliency detection technique that incorporates both spatial and temporal information for detecting static, dynamic geometric, and color salient regions. Finally, we intelligently fuse saliency and trajectory information to achieve more accurate viewport prediction. We conduct extensive simulations to evaluate the effectiveness of our proposed viewport prediction methods using state-of-the-art volumetric video sequences. The experimental results show the superiority of the proposed method over existing schemes. The dataset and source code will be publicly accessible after acceptance.
Salient Object Detection in Optical Remote Sensing Images Driven by Transformer
Sep 15, 2023
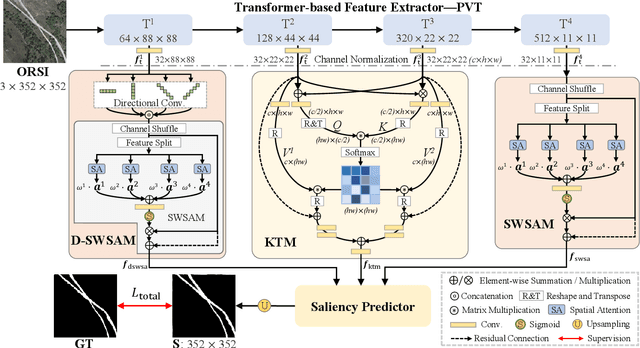
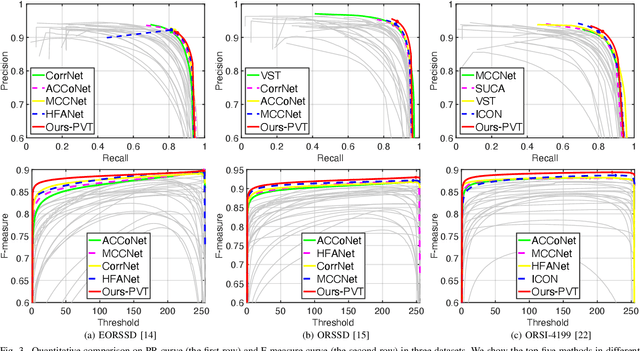

Existing methods for Salient Object Detection in Optical Remote Sensing Images (ORSI-SOD) mainly adopt Convolutional Neural Networks (CNNs) as the backbone, such as VGG and ResNet. Since CNNs can only extract features within certain receptive fields, most ORSI-SOD methods generally follow the local-to-contextual paradigm. In this paper, we propose a novel Global Extraction Local Exploration Network (GeleNet) for ORSI-SOD following the global-to-local paradigm. Specifically, GeleNet first adopts a transformer backbone to generate four-level feature embeddings with global long-range dependencies. Then, GeleNet employs a Direction-aware Shuffle Weighted Spatial Attention Module (D-SWSAM) and its simplified version (SWSAM) to enhance local interactions, and a Knowledge Transfer Module (KTM) to further enhance cross-level contextual interactions. D-SWSAM comprehensively perceives the orientation information in the lowest-level features through directional convolutions to adapt to various orientations of salient objects in ORSIs, and effectively enhances the details of salient objects with an improved attention mechanism. SWSAM discards the direction-aware part of D-SWSAM to focus on localizing salient objects in the highest-level features. KTM models the contextual correlation knowledge of two middle-level features of different scales based on the self-attention mechanism, and transfers the knowledge to the raw features to generate more discriminative features. Finally, a saliency predictor is used to generate the saliency map based on the outputs of the above three modules. Extensive experiments on three public datasets demonstrate that the proposed GeleNet outperforms relevant state-of-the-art methods. The code and results of our method are available at https://github.com/MathLee/GeleNet.
No-Service Rail Surface Defect Segmentation via Normalized Attention and Dual-scale Interaction
Jun 27, 2023



No-service rail surface defect (NRSD) segmentation is an essential way for perceiving the quality of no-service rails. However, due to the complex and diverse outlines and low-contrast textures of no-service rails, existing natural image segmentation methods cannot achieve promising performance in NRSD images, especially in some unique and challenging NRSD scenes. To this end, in this paper, we propose a novel segmentation network for NRSDs based on Normalized Attention and Dual-scale Interaction, named NaDiNet. Specifically, NaDiNet follows the enhancement-interaction paradigm. The Normalized Channel-wise Self-Attention Module (NAM) and the Dual-scale Interaction Block (DIB) are two key components of NaDiNet. NAM is a specific extension of the channel-wise self-attention mechanism (CAM) to enhance features extracted from low-contrast NRSD images. The softmax layer in CAM will produce very small correlation coefficients which are not conducive to low-contrast feature enhancement. Instead, in NAM, we directly calculate the normalized correlation coefficient between channels to enlarge the feature differentiation. DIB is specifically designed for the feature interaction of the enhanced features. It has two interaction branches with dual scales, one for fine-grained clues and the other for coarse-grained clues. With both branches working together, DIB can perceive defect regions of different granularities. With these modules working together, our NaDiNet can generate accurate segmentation map. Extensive experiments on the public NRSD-MN dataset with man-made and natural NRSDs demonstrate that our proposed NaDiNet with various backbones (i.e., VGG, ResNet, and DenseNet) consistently outperforms 10 state-of-the-art methods. The code and results of our method are available at https://github.com/monxxcn/NaDiNet.
Deep Neural Networks in Video Human Action Recognition: A Review
May 25, 2023



Currently, video behavior recognition is one of the most foundational tasks of computer vision. The 2D neural networks of deep learning are built for recognizing pixel-level information such as images with RGB, RGB-D, or optical flow formats, with the current increasingly wide usage of surveillance video and more tasks related to human action recognition. There are increasing tasks requiring temporal information for frames dependency analysis. The researchers have widely studied video-based recognition rather than image-based(pixel-based) only to extract more informative elements from geometry tasks. Our current related research addresses multiple novel proposed research works and compares their advantages and disadvantages between the derived deep learning frameworks rather than machine learning frameworks. The comparison happened between existing frameworks and datasets, which are video format data only. Due to the specific properties of human actions and the increasingly wide usage of deep neural networks, we collected all research works within the last three years between 2020 to 2022. In our article, the performance of deep neural networks surpassed most of the techniques in the feature learning and extraction tasks, especially video action recognition.
Shared and Private Information Learning in Multimodal Sentiment Analysis with Deep Modal Alignment and Self-supervised Multi-Task Learning
May 15, 2023



Designing an effective representation learning method for multimodal sentiment analysis tasks is a crucial research direction. The challenge lies in learning both shared and private information in a complete modal representation, which is difficult with uniform multimodal labels and a raw feature fusion approach. In this work, we propose a deep modal shared information learning module based on the covariance matrix to capture the shared information between modalities. Additionally, we use a label generation module based on a self-supervised learning strategy to capture the private information of the modalities. Our module is plug-and-play in multimodal tasks, and by changing the parameterization, it can adjust the information exchange relationship between the modes and learn the private or shared information between the specified modes. We also employ a multi-task learning strategy to help the model focus its attention on the modal differentiation training data. We provide a detailed formulation derivation and feasibility proof for the design of the deep modal shared information learning module. We conduct extensive experiments on three common multimodal sentiment analysis baseline datasets, and the experimental results validate the reliability of our model. Furthermore, we explore more combinatorial techniques for the use of the module. Our approach outperforms current state-of-the-art methods on most of the metrics of the three public datasets.
Multimodal Sentiment Analysis: A Survey
May 12, 2023



Multimodal sentiment analysis has become an important research area in the field of artificial intelligence. With the latest advances in deep learning, this technology has reached new heights. It has great potential for both application and research, making it a popular research topic. This review provides an overview of the definition, background, and development of multimodal sentiment analysis. It also covers recent datasets and advanced models, emphasizing the challenges and future prospects of this technology. Finally, it looks ahead to future research directions. It should be noted that this review provides constructive suggestions for promising research directions and building better performing multimodal sentiment analysis models, which can help researchers in this field.
SGDA: Towards 3D Universal Pulmonary Nodule Detection via Slice Grouped Domain Attention
Mar 07, 2023



Lung cancer is the leading cause of cancer death worldwide. The best solution for lung cancer is to diagnose the pulmonary nodules in the early stage, which is usually accomplished with the aid of thoracic computed tomography (CT). As deep learning thrives, convolutional neural networks (CNNs) have been introduced into pulmonary nodule detection to help doctors in this labor-intensive task and demonstrated to be very effective. However, the current pulmonary nodule detection methods are usually domain-specific, and cannot satisfy the requirement of working in diverse real-world scenarios. To address this issue, we propose a slice grouped domain attention (SGDA) module to enhance the generalization capability of the pulmonary nodule detection networks. This attention module works in the axial, coronal, and sagittal directions. In each direction, we divide the input feature into groups, and for each group, we utilize a universal adapter bank to capture the feature subspaces of the domains spanned by all pulmonary nodule datasets. Then the bank outputs are combined from the perspective of domain to modulate the input group. Extensive experiments demonstrate that SGDA enables substantially better multi-domain pulmonary nodule detection performance compared with the state-of-the-art multi-domain learning methods.