 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAndrea Cavallaro
Sparse multi-view hand-object reconstruction for unseen environments
May 02, 2024
Recent works in hand-object reconstruction mainly focus on the single-view and dense multi-view settings. On the one hand, single-view methods can leverage learned shape priors to generalise to unseen objects but are prone to inaccuracies due to occlusions. On the other hand, dense multi-view methods are very accurate but cannot easily adapt to unseen objects without further data collection. In contrast, sparse multi-view methods can take advantage of the additional views to tackle occlusion, while keeping the computational cost low compared to dense multi-view methods. In this paper, we consider the problem of hand-object reconstruction with unseen objects in the sparse multi-view setting. Given multiple RGB images of the hand and object captured at the same time, our model SVHO combines the predictions from each view into a unified reconstruction without optimisation across views. We train our model on a synthetic hand-object dataset and evaluate directly on a real world recorded hand-object dataset with unseen objects. We show that while reconstruction of unseen hands and objects from RGB is challenging, additional views can help improve the reconstruction quality.
Explaining models relating objects and privacy
May 02, 2024Accurately predicting whether an image is private before sharing it online is difficult due to the vast variety of content and the subjective nature of privacy itself. In this paper, we evaluate privacy models that use objects extracted from an image to determine why the image is predicted as private. To explain the decision of these models, we use feature-attribution to identify and quantify which objects (and which of their features) are more relevant to privacy classification with respect to a reference input (i.e., no objects localised in an image) predicted as public. We show that the presence of the person category and its cardinality is the main factor for the privacy decision. Therefore, these models mostly fail to identify private images depicting documents with sensitive data, vehicle ownership, and internet activity, or public images with people (e.g., an outdoor concert or people walking in a public space next to a famous landmark). As baselines for future benchmarks, we also devise two strategies that are based on the person presence and cardinality and achieve comparable classification performance of the privacy models.
Open-vocabulary object 6D pose estimation
Dec 07, 2023We introduce the new setting of open-vocabulary object 6D pose estimation, in which a textual prompt is used to specify the object of interest. In contrast to existing approaches, in our setting (i) the object of interest is specified solely through the textual prompt, (ii) no object model (e.g. CAD or video sequence) is required at inference, (iii) the object is imaged from two different viewpoints of two different scenes, and (iv) the object was not observed during the training phase. To operate in this setting, we introduce a novel approach that leverages a Vision-Language Model to segment the object of interest from two distinct scenes and to estimate its relative 6D pose. The key of our approach is a carefully devised strategy to fuse object-level information provided by the prompt with local image features, resulting in a feature space that can generalize to novel concepts. We validate our approach on a new benchmark based on two popular datasets, REAL275 and Toyota-Light, which collectively encompass 39 object instances appearing in four thousand image pairs. The results demonstrate that our approach outperforms both a well-established hand-crafted method and a recent deep learning-based baseline in estimating the relative 6D pose of objects in different scenes. Project page: https://jcorsetti.github.io/oryon/.
Human-interpretable and deep features for image privacy classification
Oct 31, 2023Privacy is a complex, subjective and contextual concept that is difficult to define. Therefore, the annotation of images to train privacy classifiers is a challenging task. In this paper, we analyse privacy classification datasets and the properties of controversial images that are annotated with contrasting privacy labels by different assessors. We discuss suitable features for image privacy classification and propose eight privacy-specific and human-interpretable features. These features increase the performance of deep learning models and, on their own, improve the image representation for privacy classification compared with much higher dimensional deep features.
Black-box Attacks on Image Activity Prediction and its Natural Language Explanations
Sep 30, 2023Explainable AI (XAI) methods aim to describe the decision process of deep neural networks. Early XAI methods produced visual explanations, whereas more recent techniques generate multimodal explanations that include textual information and visual representations. Visual XAI methods have been shown to be vulnerable to white-box and gray-box adversarial attacks, with an attacker having full or partial knowledge of and access to the target system. As the vulnerabilities of multimodal XAI models have not been examined, in this paper we assess for the first time the robustness to black-box attacks of the natural language explanations generated by a self-rationalizing image-based activity recognition model. We generate unrestricted, spatially variant perturbations that disrupt the association between the predictions and the corresponding explanations to mislead the model into generating unfaithful explanations. We show that we can create adversarial images that manipulate the explanations of an activity recognition model by having access only to its final output.
Affordance segmentation of hand-occluded containers from exocentric images
Aug 22, 2023



Visual affordance segmentation identifies the surfaces of an object an agent can interact with. Common challenges for the identification of affordances are the variety of the geometry and physical properties of these surfaces as well as occlusions. In this paper, we focus on occlusions of an object that is hand-held by a person manipulating it. To address this challenge, we propose an affordance segmentation model that uses auxiliary branches to process the object and hand regions separately. The proposed model learns affordance features under hand-occlusion by weighting the feature map through hand and object segmentation. To train the model, we annotated the visual affordances of an existing dataset with mixed-reality images of hand-held containers in third-person (exocentric) images. Experiments on both real and mixed-reality images show that our model achieves better affordance segmentation and generalisation than existing models.
A mixed-reality dataset for category-level 6D pose and size estimation of hand-occluded containers
Nov 18, 2022



Estimating the 6D pose and size of household containers is challenging due to large intra-class variations in the object properties, such as shape, size, appearance, and transparency. The task is made more difficult when these objects are held and manipulated by a person due to varying degrees of hand occlusions caused by the type of grasps and by the viewpoint of the camera observing the person holding the object. In this paper, we present a mixed-reality dataset of hand-occluded containers for category-level 6D object pose and size estimation. The dataset consists of 138,240 images of rendered hands and forearms holding 48 synthetic objects, split into 3 grasp categories over 30 real backgrounds. We re-train and test an existing model for 6D object pose estimation on our mixed-reality dataset. We discuss the impact of the use of this dataset in improving the task of 6D pose and size estimation.
Content-based Graph Privacy Advisor
Oct 20, 2022
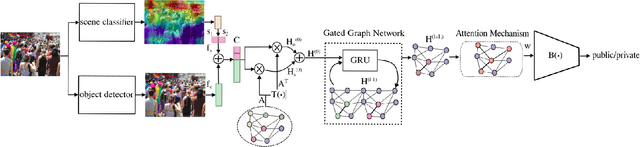


People may be unaware of the privacy risks of uploading an image online. In this paper, we present an image privacy classifier that uses scene information and object cardinality as cues for the prediction of image privacy. Our Graph Privacy Advisor (GPA) model simplifies a state-of-the-art graph model and improves its performance by refining the relevance of the content-based information extracted from the image. We determine the most informative visual features to be used for the privacy classification task and reduce the complexity of the model by replacing high-dimensional image-based feature vectors with lower-dimensional, more effective features. We also address the biased prior information by modelling object co-occurrences instead of the frequency of object occurrences in each class.
BON: An extended public domain dataset for human activity recognition
Sep 12, 2022



Body-worn first-person vision (FPV) camera enables to extract a rich source of information on the environment from the subject's viewpoint. However, the research progress in wearable camera-based egocentric office activity understanding is slow compared to other activity environments (e.g., kitchen and outdoor ambulatory), mainly due to the lack of adequate datasets to train more sophisticated (e.g., deep learning) models for human activity recognition in office environments. This paper provides details of a large and publicly available office activity dataset (BON) collected in different office settings across three geographical locations: Barcelona (Spain), Oxford (UK) and Nairobi (Kenya), using a chest-mounted GoPro Hero camera. The BON dataset contains eighteen common office activities that can be categorised into person-to-person interactions (e.g., Chat with colleagues), person-to-object (e.g., Writing on a whiteboard), and proprioceptive (e.g., Walking). Annotation is provided for each segment of video with 5-seconds duration. Generally, BON contains 25 subjects and 2639 total segments. In order to facilitate further research in the sub-domain, we have also provided results that could be used as baselines for future studies.
Cross-Camera View-Overlap Recognition
Aug 24, 2022



We propose a decentralised view-overlap recognition framework that operates across freely moving cameras without the need of a reference 3D map. Each camera independently extracts, aggregates into a hierarchical structure, and shares feature-point descriptors over time. A view overlap is recognised by view-matching and geometric validation to discard wrongly matched views. The proposed framework is generic and can be used with different descriptors. We conduct the experiments on publicly available sequences as well as new sequences we collected with hand-held cameras. We show that Oriented FAST and Rotated BRIEF (ORB) features with Bags of Binary Words within the proposed framework lead to higher precision and a higher or similar accuracy compared to NetVLAD, RootSIFT, and SuperGlue.