 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLi-Chun Zhang
Design-based individual prediction
Jan 22, 2023


A design-based individual prediction approach is developed based on the expected cross-validation results, given the sampling design and the sample-splitting design for cross-validation. Whether the predictor is selected from an ensemble of models or a weighted average of them, valid inference of the unobserved prediction errors is defined and obtained with respect to the sampling design, while outcomes and features are treated as constants.
Graph sampling for node embedding
Oct 19, 2022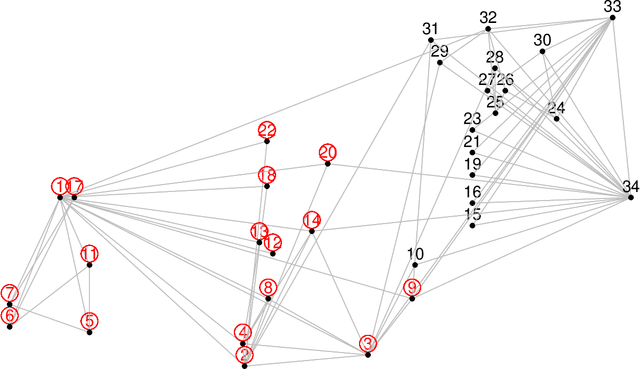
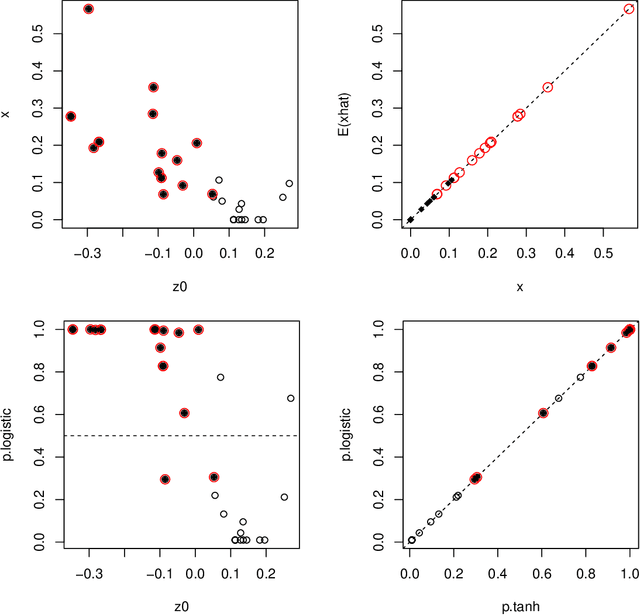
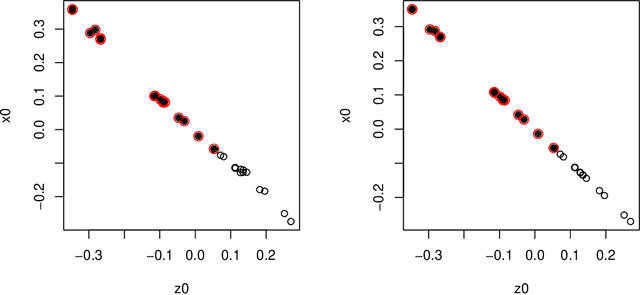
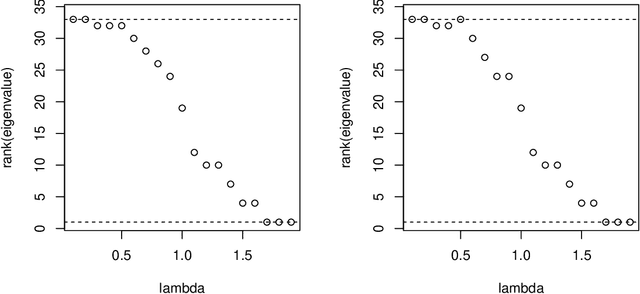
Node embedding is a central topic in graph representation learning. Computational efficiency and scalability can be challenging to any method that requires full-graph operations. We propose sampling approaches to node embedding, with or without explicit modelling of the feature vector, which aim to extract useful information from both the eigenvectors related to the graph Laplacien and the given values associated with the graph.
Sampling for network function learning
Sep 11, 2022Given a valued graph, where both the nodes and the edges of the graph are associated with one or several values, any network function for a given node must be defined in terms of that node and its connected nodes in the graph. Generally, applying the same definition to the whole graph or any given subgraph of it would result in systematically different network functions. In this paper we consider the feasibility of graph sampling approach to network function learning, as well as the corresponding learning methods based on the sample graphs. This can be useful either when the edges are unknown to start with or the graph is too large (or dynamic) to be processed entirely.
Design-unbiased statistical learning in survey sampling
Mar 25, 2020



Design-consistent model-assisted estimation has become the standard practice in survey sampling. However, a general theory is lacking so far, which allows one to incorporate modern machine-learning techniques that can lead to potentially much more powerful assisting models. We propose a subsampling Rao-Blackwell method, and develop a statistical learning theory for exactly design-unbiased estimation with the help of linear or non-linear prediction models. Our approach makes use of classic ideas from Statistical Science as well as the rapidly growing field of Machine Learning. Provided rich auxiliary information, it can yield considerable efficiency gains over standard linear model-assisted methods, while ensuring valid estimation for the given target population, which is robust against potential mis-specifications of the assisting model at the individual level.