 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
New Foggy Object Detecting Model
Jan 27, 2024
Object detection in reduced visibility has become a prominent research area. The existing techniques are not accurate enough in recognizing objects under such circumstances. This paper introduces a new foggy object detection method through a two-staged architecture of region identification from input images and detecting objects in such regions. The paper confirms notable improvements of the proposed method's accuracy and detection time over existing techniques.
Hybrid Pooling and Convolutional Network for Improving Accuracy and Training Convergence Speed in Object Detection
Jan 02, 2024This paper introduces HPC-Net, a high-precision and rapidly convergent object detection network.
Fast Quantum Convolutional Neural Networks for Low-Complexity Object Detection in Autonomous Driving Applications
Dec 28, 2023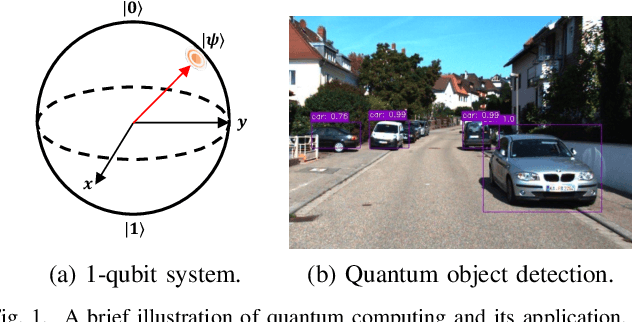
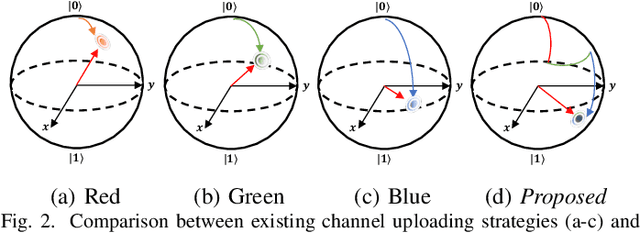
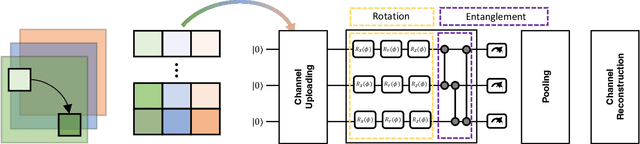
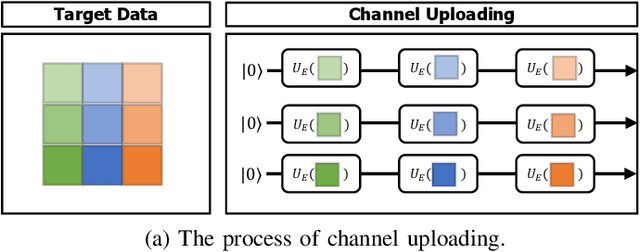
Spurred by consistent advances and innovation in deep learning, object detection applications have become prevalent, particularly in autonomous driving that leverages various visual data. As convolutional neural networks (CNNs) are being optimized, the performances and computation speeds of object detection in autonomous driving have been significantly improved. However, due to the exponentially rapid growth in the complexity and scale of data used in object detection, there are limitations in terms of computation speeds while conducting object detection solely with classical computing. Motivated by this, quantum convolution-based object detection (QCOD) is proposed to adopt quantum computing to perform object detection at high speed. The QCOD utilizes our proposed fast quantum convolution that uploads input channel information and re-constructs output channels for achieving reduced computational complexity and thus improving performances. Lastly, the extensive experiments with KITTI autonomous driving object detection dataset verify that the proposed fast quantum convolution and QCOD are successfully operated in real object detection applications.
Knowledge Graph Driven UAV Cognitive Semantic Communication Systems for Efficient Object Detection
Jan 25, 2024Unmanned aerial vehicles (UAVs) are widely used for object detection. However, the existing UAV-based object detection systems are subject to the serious challenge, namely, the finite computation, energy and communication resources, which limits the achievable detection performance. In order to overcome this challenge, a UAV cognitive semantic communication system is proposed by exploiting knowledge graph. Moreover, a multi-scale compression network is designed for semantic compression to reduce data transmission volume while guaranteeing the detection performance. Furthermore, an object detection scheme is proposed by using the knowledge graph to overcome channel noise interference and compression distortion. Simulation results conducted on the practical aerial image dataset demonstrate that compared to the benchmark systems, our proposed system has superior detection accuracy, communication robustness and computation efficiency even under high compression rates and low signal-to-noise ratio (SNR) conditions.
Enhancing Lidar-based Object Detection in Adverse Weather using Offset Sequences in Time
Jan 17, 2024Automated vehicles require an accurate perception of their surroundings for safe and efficient driving. Lidar-based object detection is a widely used method for environment perception, but its performance is significantly affected by adverse weather conditions such as rain and fog. In this work, we investigate various strategies for enhancing the robustness of lidar-based object detection by processing sequential data samples generated by lidar sensors. Our approaches leverage temporal information to improve a lidar object detection model, without the need for additional filtering or pre-processing steps. We compare $10$ different neural network architectures that process point cloud sequences including a novel augmentation strategy introducing a temporal offset between frames of a sequence during training and evaluate the effectiveness of all strategies on lidar point clouds under adverse weather conditions through experiments. Our research provides a comprehensive study of effective methods for mitigating the effects of adverse weather on the reliability of lidar-based object detection using sequential data that are evaluated using public datasets such as nuScenes, Dense, and the Canadian Adverse Driving Conditions Dataset. Our findings demonstrate that our novel method, involving temporal offset augmentation through randomized frame skipping in sequences, enhances object detection accuracy compared to both the baseline model (Pillar-based Object Detection) and no augmentation.
Measuring the Impact of Scene Level Objects on Object Detection: Towards Quantitative Explanations of Detection Decisions
Jan 19, 2024Although accuracy and other common metrics can provide a useful window into the performance of an object detection model, they lack a deeper view of the model's decision process. Regardless of the quality of the training data and process, the features that an object detection model learns cannot be guaranteed. A model may learn a relationship between certain background context, i.e., scene level objects, and the presence of the labeled classes. Furthermore, standard performance verification and metrics would not identify this phenomenon. This paper presents a new black box explainability method for additional verification of object detection models by finding the impact of scene level objects on the identification of the objects within the image. By comparing the accuracies of a model on test data with and without certain scene level objects, the contributions of these objects to the model's performance becomes clearer. The experiment presented here will assess the impact of buildings and people in image context on the detection of emergency road vehicles by a fine-tuned YOLOv8 model. A large increase in accuracy in the presence of a scene level object will indicate the model's reliance on that object to make its detections. The results of this research lead to providing a quantitative explanation of the object detection model's decision process, enabling a deeper understanding of the model's performance.
From Blurry to Brilliant Detection: YOLOv5-Based Aerial Object Detection with Super Resolution
Jan 26, 2024The demand for accurate object detection in aerial imagery has surged with the widespread use of drones and satellite technology. Traditional object detection models, trained on datasets biased towards large objects, struggle to perform optimally in aerial scenarios where small, densely clustered objects are prevalent. To address this challenge, we present an innovative approach that combines super-resolution and an adapted lightweight YOLOv5 architecture. We employ a range of datasets, including VisDrone-2023, SeaDroneSee, VEDAI, and NWPU VHR-10, to evaluate our model's performance. Our Super Resolved YOLOv5 architecture features Transformer encoder blocks, allowing the model to capture global context and context information, leading to improved detection results, especially in high-density, occluded conditions. This lightweight model not only delivers improved accuracy but also ensures efficient resource utilization, making it well-suited for real-time applications. Our experimental results demonstrate the model's superior performance in detecting small and densely clustered objects, underlining the significance of dataset choice and architectural adaptation for this specific task. In particular, the method achieves 52.5% mAP on VisDrone, exceeding top prior works. This approach promises to significantly advance object detection in aerial imagery, contributing to more accurate and reliable results in a variety of real-world applications.
You Only Look Bottom-Up for Monocular 3D Object Detection
Jan 27, 2024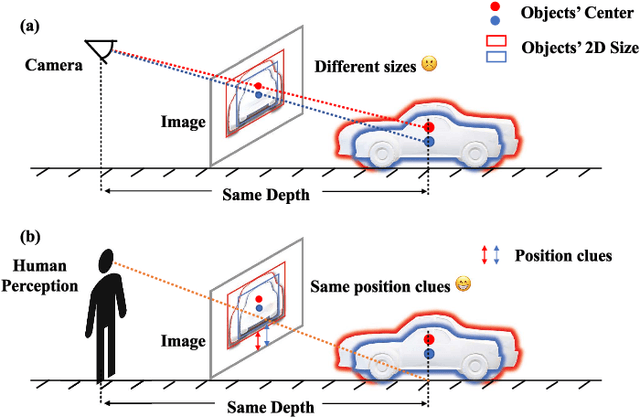
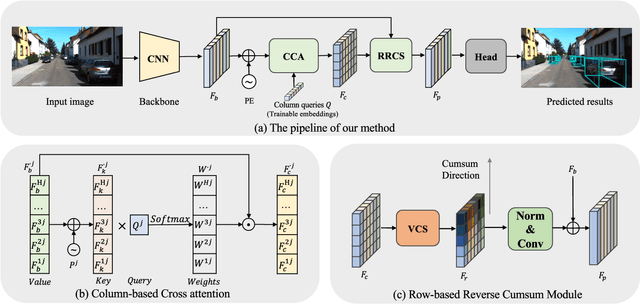
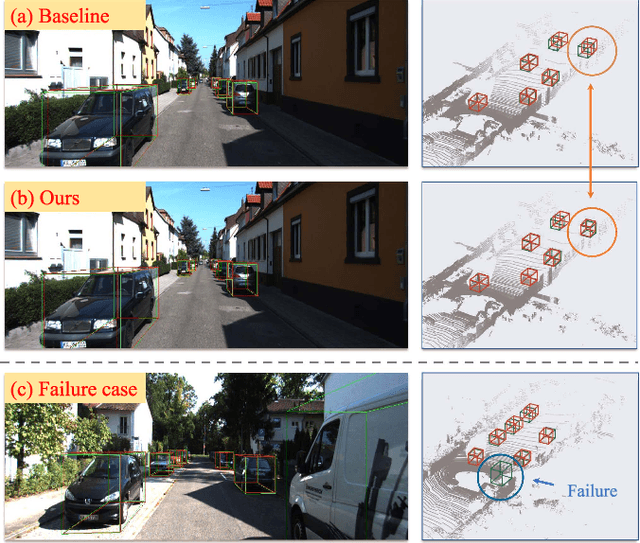
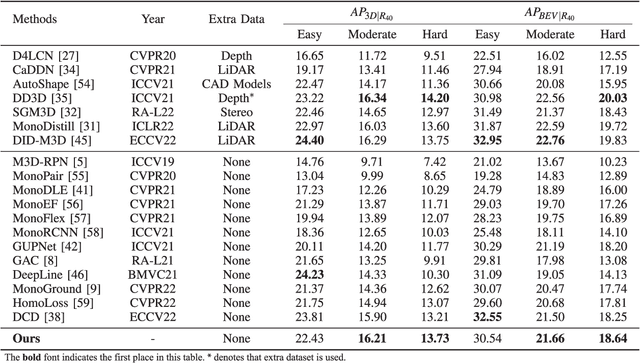
Monocular 3D Object Detection is an essential task for autonomous driving. Meanwhile, accurate 3D object detection from pure images is very challenging due to the loss of depth information. Most existing image-based methods infer objects' location in 3D space based on their 2D sizes on the image plane, which usually ignores the intrinsic position clues from images, leading to unsatisfactory performances. Motivated by the fact that humans could leverage the bottom-up positional clues to locate objects in 3D space from a single image, in this paper, we explore the position modeling from the image feature column and propose a new method named You Only Look Bottum-Up (YOLOBU). Specifically, our YOLOBU leverages Column-based Cross Attention to determine how much a pixel contributes to pixels above it. Next, the Row-based Reverse Cumulative Sum (RRCS) is introduced to build the connections of pixels in the bottom-up direction. Our YOLOBU fully explores the position clues for monocular 3D detection via building the relationship of pixels from the bottom-up way. Extensive experiments on the KITTI dataset demonstrate the effectiveness and superiority of our method.
Small Object Detection by DETR via Information Augmentation and Adaptive Feature Fusion
Jan 16, 2024The main challenge for small object detection algorithms is to ensure accuracy while pursuing real-time performance. The RT-DETR model performs well in real-time object detection, but performs poorly in small object detection accuracy. In order to compensate for the shortcomings of the RT-DETR model in small object detection, two key improvements are proposed in this study. Firstly, The RT-DETR utilises a Transformer that receives input solely from the final layer of Backbone features. This means that the Transformer's input only receives semantic information from the highest level of abstraction in the Deep Network, and ignores detailed information such as edges, texture or color gradients that are critical to the location of small objects at lower levels of abstraction. Including only deep features can introduce additional background noise. This can have a negative impact on the accuracy of small object detection. To address this issue, we propose the fine-grained path augmentation method. This method helps to locate small objects more accurately by providing detailed information to the deep network. So, the input to the transformer contains both semantic and detailed information. Secondly, In RT-DETR, the decoder takes feature maps of different levels as input after concatenating them with equal weight. However, this operation is not effective in dealing with the complex relationship of multi-scale information captured by feature maps of different sizes. Therefore, we propose an adaptive feature fusion algorithm that assigns learnable parameters to each feature map from different levels. This allows the model to adaptively fuse feature maps from different levels and effectively integrate feature information from different scales. This enhances the model's ability to capture object features at different scales, thereby improving the accuracy of detecting small objects.
Robustness-Aware 3D Object Detection in Autonomous Driving: A Review and Outlook
Jan 12, 2024In the realm of modern autonomous driving, the perception system is indispensable for accurately assessing the state of the surrounding environment, thereby enabling informed prediction and planning. Key to this system is 3D object detection methods, that utilize vehicle-mounted sensors such as LiDAR and cameras to identify the size, category, and location of nearby objects. Despite the surge in 3D object detection methods aimed at enhancing detection precision and efficiency, there is a gap in the literature that systematically examines their resilience against environmental variations, noise, and weather changes. This study emphasizes the importance of robustness, alongside accuracy and latency, in evaluating perception systems under practical scenarios. Our work presents an extensive survey of camera-based, LiDAR-based, and multimodal 3D object detection algorithms, thoroughly evaluating their trade-off between accuracy, latency, and robustness, particularly on datasets like KITTI-C and nuScenes-C to ensure fair comparisons. Among these,multimodal 3D detection approaches exhibit superior robustness and a novel taxonomy is introduced to reorganize its literature for enhanced clarity. This survey aims to offer a more practical perspective on the current capabilities and constraints of 3D object detection algorithms in real-world applications, thus steering future research towards robustness-centric advancements