 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYaowei Wang
Prompt Customization for Continual Learning
Apr 28, 2024
Contemporary continual learning approaches typically select prompts from a pool, which function as supplementary inputs to a pre-trained model. However, this strategy is hindered by the inherent noise of its selection approach when handling increasing tasks. In response to these challenges, we reformulate the prompting approach for continual learning and propose the prompt customization (PC) method. PC mainly comprises a prompt generation module (PGM) and a prompt modulation module (PMM). In contrast to conventional methods that employ hard prompt selection, PGM assigns different coefficients to prompts from a fixed-sized pool of prompts and generates tailored prompts. Moreover, PMM further modulates the prompts by adaptively assigning weights according to the correlations between input data and corresponding prompts. We evaluate our method on four benchmark datasets for three diverse settings, including the class, domain, and task-agnostic incremental learning tasks. Experimental results demonstrate consistent improvement (by up to 16.2\%), yielded by the proposed method, over the state-of-the-art (SOTA) techniques.
Spatio-Temporal Side Tuning Pre-trained Foundation Models for Video-based Pedestrian Attribute Recognition
Apr 27, 2024Existing pedestrian attribute recognition (PAR) algorithms are mainly developed based on a static image, however, the performance is unreliable in challenging scenarios, such as heavy occlusion, motion blur, etc. In this work, we propose to understand human attributes using video frames that can fully use temporal information by fine-tuning a pre-trained multi-modal foundation model efficiently. Specifically, we formulate the video-based PAR as a vision-language fusion problem and adopt a pre-trained foundation model CLIP to extract the visual features. More importantly, we propose a novel spatiotemporal side-tuning strategy to achieve parameter-efficient optimization of the pre-trained vision foundation model. To better utilize the semantic information, we take the full attribute list that needs to be recognized as another input and transform the attribute words/phrases into the corresponding sentence via split, expand, and prompt operations. Then, the text encoder of CLIP is utilized for embedding processed attribute descriptions. The averaged visual tokens and text tokens are concatenated and fed into a fusion Transformer for multi-modal interactive learning. The enhanced tokens will be fed into a classification head for pedestrian attribute prediction. Extensive experiments on two large-scale video-based PAR datasets fully validated the effectiveness of our proposed framework. The source code of this paper is available at https://github.com/Event-AHU/OpenPAR.
Motion-aware Latent Diffusion Models for Video Frame Interpolation
Apr 21, 2024With the advancement of AIGC, video frame interpolation (VFI) has become a crucial component in existing video generation frameworks, attracting widespread research interest. For the VFI task, the motion estimation between neighboring frames plays a crucial role in avoiding motion ambiguity. However, existing VFI methods always struggle to accurately predict the motion information between consecutive frames, and this imprecise estimation leads to blurred and visually incoherent interpolated frames. In this paper, we propose a novel diffusion framework, motion-aware latent diffusion models (MADiff), which is specifically designed for the VFI task. By incorporating motion priors between the conditional neighboring frames with the target interpolated frame predicted throughout the diffusion sampling procedure, MADiff progressively refines the intermediate outcomes, culminating in generating both visually smooth and realistic results. Extensive experiments conducted on benchmark datasets demonstrate that our method achieves state-of-the-art performance significantly outperforming existing approaches, especially under challenging scenarios involving dynamic textures with complex motion.
HiVG: Hierarchical Multimodal Fine-grained Modulation for Visual Grounding
Apr 20, 2024Visual grounding, which aims to ground a visual region via natural language, is a task that heavily relies on cross-modal alignment. Existing works utilized uni-modal pre-trained models to transfer visual/linguistic knowledge separately while ignoring the multimodal corresponding information. Motivated by recent advancements in contrastive language-image pre-training and low-rank adaptation (LoRA) methods, we aim to solve the grounding task based on multimodal pre-training. However, there exists significant task gaps between pre-training and grounding. Therefore, to address these gaps, we propose a concise and efficient hierarchical multimodal fine-grained modulation framework, namely HiVG. Specifically, HiVG consists of a multi-layer adaptive cross-modal bridge and a hierarchical multimodal low-rank adaptation (Hi LoRA) paradigm. The cross-modal bridge can address the inconsistency between visual features and those required for grounding, and establish a connection between multi-level visual and text features. Hi LoRA prevents the accumulation of perceptual errors by adapting the cross-modal features from shallow to deep layers in a hierarchical manner. Experimental results on five datasets demonstrate the effectiveness of our approach and showcase the significant grounding capabilities as well as promising energy efficiency advantages. The project page: https://github.com/linhuixiao/HiVG.
State Space Model for New-Generation Network Alternative to Transformers: A Survey
Apr 15, 2024In the post-deep learning era, the Transformer architecture has demonstrated its powerful performance across pre-trained big models and various downstream tasks. However, the enormous computational demands of this architecture have deterred many researchers. To further reduce the complexity of attention models, numerous efforts have been made to design more efficient methods. Among them, the State Space Model (SSM), as a possible replacement for the self-attention based Transformer model, has drawn more and more attention in recent years. In this paper, we give the first comprehensive review of these works and also provide experimental comparisons and analysis to better demonstrate the features and advantages of SSM. Specifically, we first give a detailed description of principles to help the readers quickly capture the key ideas of SSM. After that, we dive into the reviews of existing SSMs and their various applications, including natural language processing, computer vision, graph, multi-modal and multi-media, point cloud/event stream, time series data, and other domains. In addition, we give statistical comparisons and analysis of these models and hope it helps the readers to understand the effectiveness of different structures on various tasks. Then, we propose possible research points in this direction to better promote the development of the theoretical model and application of SSM. More related works will be continuously updated on the following GitHub: https://github.com/Event-AHU/Mamba_State_Space_Model_Paper_List.
StoryImager: A Unified and Efficient Framework for Coherent Story Visualization and Completion
Apr 09, 2024Story visualization aims to generate a series of realistic and coherent images based on a storyline. Current models adopt a frame-by-frame architecture by transforming the pre-trained text-to-image model into an auto-regressive manner. Although these models have shown notable progress, there are still three flaws. 1) The unidirectional generation of auto-regressive manner restricts the usability in many scenarios. 2) The additional introduced story history encoders bring an extremely high computational cost. 3) The story visualization and continuation models are trained and inferred independently, which is not user-friendly. To these ends, we propose a bidirectional, unified, and efficient framework, namely StoryImager. The StoryImager enhances the storyboard generative ability inherited from the pre-trained text-to-image model for a bidirectional generation. Specifically, we introduce a Target Frame Masking Strategy to extend and unify different story image generation tasks. Furthermore, we propose a Frame-Story Cross Attention Module that decomposes the cross attention for local fidelity and global coherence. Moreover, we design a Contextual Feature Extractor to extract contextual information from the whole storyline. The extensive experimental results demonstrate the excellent performance of our StoryImager. The code is available at https://github.com/tobran/StoryImager.
RTracker: Recoverable Tracking via PN Tree Structured Memory
Mar 28, 2024



Existing tracking methods mainly focus on learning better target representation or developing more robust prediction models to improve tracking performance. While tracking performance has significantly improved, the target loss issue occurs frequently due to tracking failures, complete occlusion, or out-of-view situations. However, considerably less attention is paid to the self-recovery issue of tracking methods, which is crucial for practical applications. To this end, we propose a recoverable tracking framework, RTracker, that uses a tree-structured memory to dynamically associate a tracker and a detector to enable self-recovery ability. Specifically, we propose a Positive-Negative Tree-structured memory to chronologically store and maintain positive and negative target samples. Upon the PN tree memory, we develop corresponding walking rules for determining the state of the target and define a set of control flows to unite the tracker and the detector in different tracking scenarios. Our core idea is to use the support samples of positive and negative target categories to establish a relative distance-based criterion for a reliable assessment of target loss. The favorable performance in comparison against the state-of-the-art methods on numerous challenging benchmarks demonstrates the effectiveness of the proposed algorithm.
Tracking Meets LoRA: Faster Training, Larger Model, Stronger Performance
Mar 08, 2024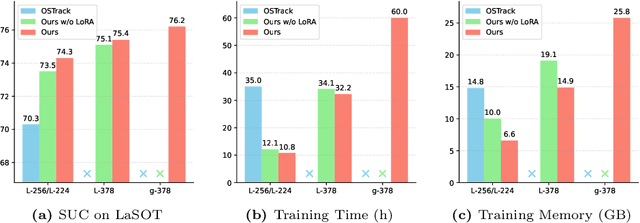
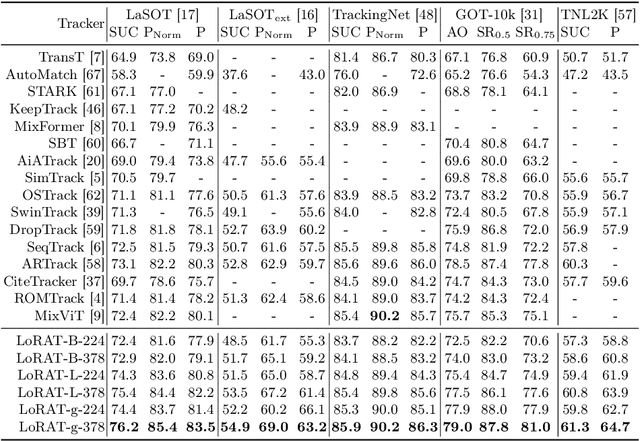
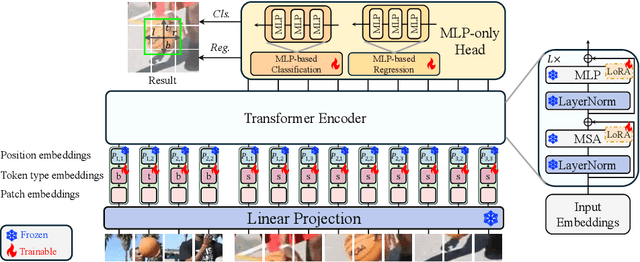
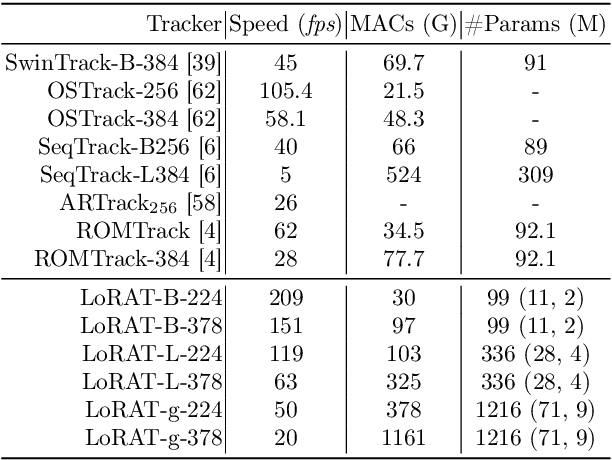
Motivated by the Parameter-Efficient Fine-Tuning (PEFT) in large language models, we propose LoRAT, a method that unveils the power of larger Vision Transformers (ViT) for tracking within laboratory-level resources. The essence of our work lies in adapting LoRA, a technique that fine-tunes a small subset of model parameters without adding inference latency, to the domain of visual tracking. However, unique challenges and potential domain gaps make this transfer not as easy as the first intuition. Firstly, a transformer-based tracker constructs unshared position embedding for template and search image. This poses a challenge for the transfer of LoRA, usually requiring consistency in the design when applied to the pre-trained backbone, to downstream tasks. Secondly, the inductive bias inherent in convolutional heads diminishes the effectiveness of parameter-efficient fine-tuning in tracking models. To overcome these limitations, we first decouple the position embeddings in transformer-based trackers into shared spatial ones and independent type ones. The shared embeddings, which describe the absolute coordinates of multi-resolution images (namely, the template and search images), are inherited from the pre-trained backbones. In contrast, the independent embeddings indicate the sources of each token and are learned from scratch. Furthermore, we design an anchor-free head solely based on a multilayer perceptron (MLP) to adapt PETR, enabling better performance with less computational overhead. With our design, 1) it becomes practical to train trackers with the ViT-g backbone on GPUs with only memory of 25.8GB (batch size of 16); 2) we reduce the training time of the L-224 variant from 35.0 to 10.8 GPU hours; 3) we improve the LaSOT SUC score from 0.703 to 0.743 with the L-224 variant; 4) we fast the inference speed of the L-224 variant from 52 to 119 FPS. Code and models will be released.
Towards Robust and Efficient Cloud-Edge Elastic Model Adaptation via Selective Entropy Distillation
Feb 29, 2024The conventional deep learning paradigm often involves training a deep model on a server and then deploying the model or its distilled ones to resource-limited edge devices. Usually, the models shall remain fixed once deployed (at least for some period) due to the potential high cost of model adaptation for both the server and edge sides. However, in many real-world scenarios, the test environments may change dynamically (known as distribution shifts), which often results in degraded performance. Thus, one has to adapt the edge models promptly to attain promising performance. Moreover, with the increasing data collected at the edge, this paradigm also fails to further adapt the cloud model for better performance. To address these, we encounter two primary challenges: 1) the edge model has limited computation power and may only support forward propagation; 2) the data transmission budget between cloud and edge devices is limited in latency-sensitive scenarios. In this paper, we establish a Cloud-Edge Elastic Model Adaptation (CEMA) paradigm in which the edge models only need to perform forward propagation and the edge models can be adapted online. In our CEMA, to reduce the communication burden, we devise two criteria to exclude unnecessary samples from uploading to the cloud, i.e., dynamic unreliable and low-informative sample exclusion. Based on the uploaded samples, we update and distribute the affine parameters of normalization layers by distilling from the stronger foundation model to the edge model with a sample replay strategy. Extensive experimental results on ImageNet-C and ImageNet-R verify the effectiveness of our CEMA.
CricaVPR: Cross-image Correlation-aware Representation Learning for Visual Place Recognition
Feb 29, 2024Over the past decade, most methods in visual place recognition (VPR) have used neural networks to produce feature representations. These networks typically produce a global representation of a place image using only this image itself and neglect the cross-image variations (e.g. viewpoint and illumination), which limits their robustness in challenging scenes. In this paper, we propose a robust global representation method with cross-image correlation awareness for VPR, named CricaVPR. Our method uses the self-attention mechanism to correlate multiple images within a batch. These images can be taken in the same place with different conditions or viewpoints, or even captured from different places. Therefore, our method can utilize the cross-image variations as a cue to guide the representation learning, which ensures more robust features are produced. To further facilitate the robustness, we propose a multi-scale convolution-enhanced adaptation method to adapt pre-trained visual foundation models to the VPR task, which introduces the multi-scale local information to further enhance the cross-image correlation-aware representation. Experimental results show that our method outperforms state-of-the-art methods by a large margin with significantly less training time. Our method achieves 94.5% R@1 on Pitts30k using 512-dim global features. The code is released at https://github.com/Lu-Feng/CricaVPR.