 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
Iterative Document-level Information Extraction via Imitation Learning
Oct 12, 2022
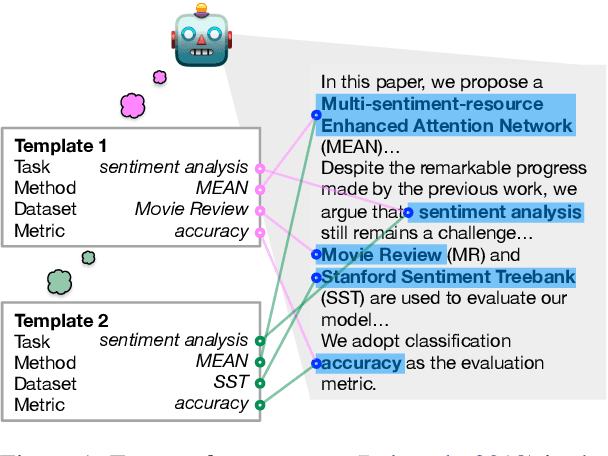
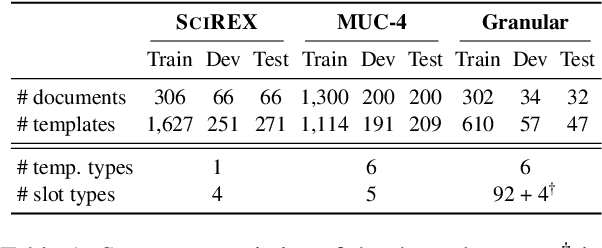

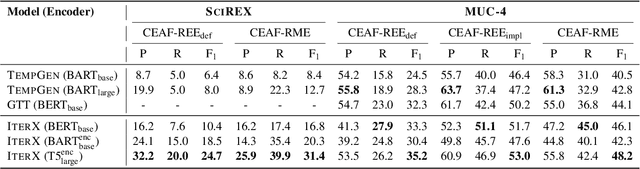
We present a novel iterative extraction (IterX) model for extracting complex relations, or templates, i.e., N-tuples representing a mapping from named slots to spans of text contained within a document. Documents may support zero or more instances of a template of any particular type, leading to the tasks of identifying the templates in a document, and extracting each template's slot values. Our imitation learning approach relieves the need to use predefined template orders to train an extractor and leads to state-of-the-art results on two established benchmarks -- 4-ary relation extraction on SciREX and template extraction on MUC-4 -- as well as a strong baseline on the new BETTER Granular task.
Key Information Extraction in Purchase Documents using Deep Learning and Rule-based Corrections
Oct 07, 2022


Deep Learning (DL) is dominating the fields of Natural Language Processing (NLP) and Computer Vision (CV) in the recent times. However, DL commonly relies on the availability of large data annotations, so other alternative or complementary pattern-based techniques can help to improve results. In this paper, we build upon Key Information Extraction (KIE) in purchase documents using both DL and rule-based corrections. Our system initially trusts on Optical Character Recognition (OCR) and text understanding based on entity tagging to identify purchase facts of interest (e.g., product codes, descriptions, quantities, or prices). These facts are then linked to a same product group, which is recognized by means of line detection and some grouping heuristics. Once these DL approaches are processed, we contribute several mechanisms consisting of rule-based corrections for improving the baseline DL predictions. We prove the enhancements provided by these rule-based corrections over the baseline DL results in the presented experiments for purchase documents from public and NielsenIQ datasets.
Schema-aware Reference as Prompt Improves Data-Efficient Relational Triple and Event Extraction
Oct 19, 2022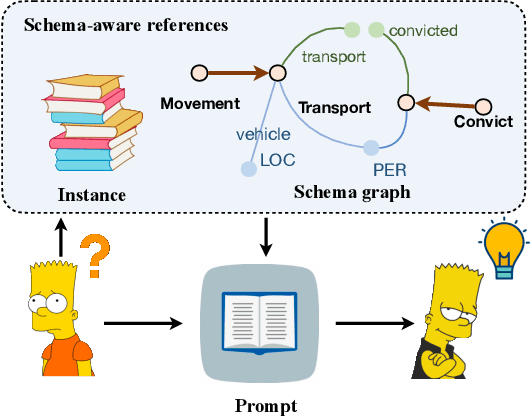
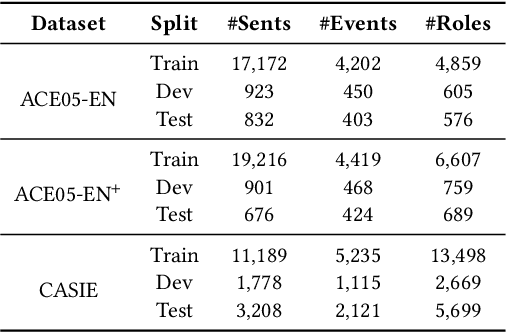
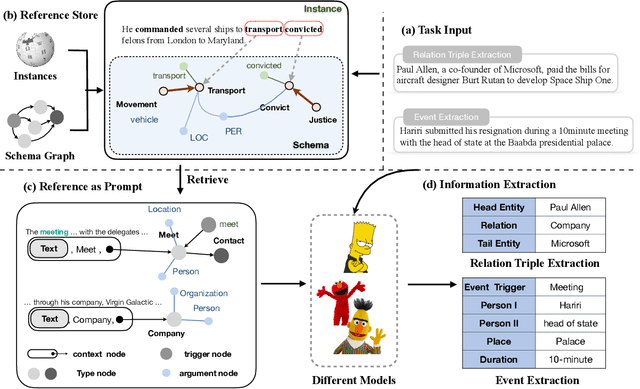
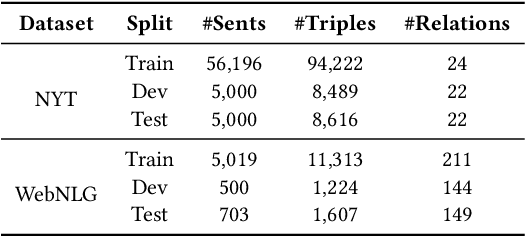
Information Extraction, which aims to extract structural relational triple or event from unstructured texts, often suffers from data scarcity issues. With the development of pre-trained language models, many prompt-based approaches to data-efficient information extraction have been proposed and achieved impressive performance. However, existing prompt learning methods for information extraction are still susceptible to several potential limitations: (i) semantic gap between natural language and output structure knowledge with pre-defined schema; (ii) representation learning with locally individual instances limits the performance given the insufficient features. In this paper, we propose a novel approach of schema-aware Reference As Prompt (RAP), which dynamically leverage schema and knowledge inherited from global (few-shot) training data for each sample. Specifically, we propose a schema-aware reference store, which unifies symbolic schema and relevant textual instances. Then, we employ a dynamic reference integration module to retrieve pertinent knowledge from the datastore as prompts during training and inference. Experimental results demonstrate that RAP can be plugged into various existing models and outperforms baselines in low-resource settings on five datasets of relational triple extraction and event extraction. In addition, we provide comprehensive empirical ablations and case analysis regarding different types and scales of knowledge in order to better understand the mechanisms of RAP. Code is available in https://github.com/zjunlp/RAP.
Cross-domain Variational Capsules for Information Extraction
Oct 13, 2022In this paper, we present a characteristic extraction algorithm and the Multi-domain Image Characteristics Dataset of characteristic-tagged images to simulate the way a human brain classifies cross-domain information and generates insight. The intent was to identify prominent characteristics in data and use this identification mechanism to auto-generate insight from data in other unseen domains. An information extraction algorithm is proposed which is a combination of Variational Autoencoders (VAEs) and Capsule Networks. Capsule Networks are used to decompose images into their individual features and VAEs are used to explore variations on these decomposed features. Thus, making the model robust in recognizing characteristics from variations of the data. A noteworthy point is that the algorithm uses efficient hierarchical decoding of data which helps in richer output interpretation. Noticing a dearth in the number of datasets that contain visible characteristics in images belonging to various domains, the Multi-domain Image Characteristics Dataset was created and made publicly available. It consists of thousands of images across three domains. This dataset was created with the intent of introducing a new benchmark for fine-grained characteristic recognition tasks in the future.
* This paper was originally written in 2020
HumSet: Dataset of Multilingual Information Extraction and Classification for Humanitarian Crisis Response
Oct 10, 2022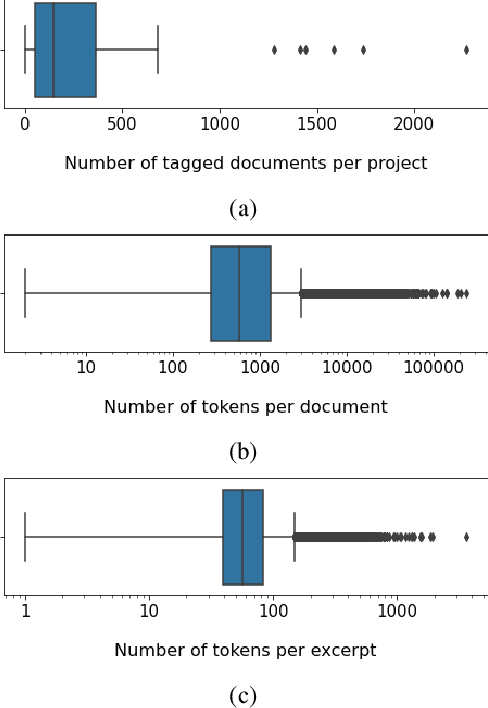

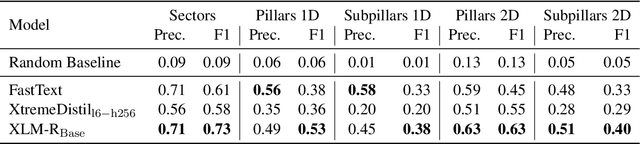
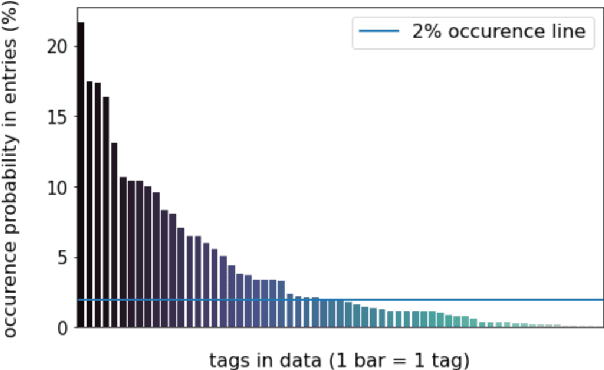
Timely and effective response to humanitarian crises requires quick and accurate analysis of large amounts of text data - a process that can highly benefit from expert - assisted NLP systems trained on validated and annotated data in the humanitarian response domain. To enable creation of such NLP systems, we introduce and release HumSet, a novel and rich multilingual dataset of humanitarian response documents annotated by experts in the humanitarian response community. The dataset provides documents in three languages (English, French, Spanish) and covers a variety of humanitarian crises from 2018 to 2021 across the globe. For each document, HumSet provides selected snippets (entries) as well as assigned classes to each entry annotated using common humanitarian information analysis frameworks. HumSet also provides novel and challenging entry extraction and multi-label entry classification tasks. In this paper, we take a first step towards approaching these tasks and conduct a set of experiments on Pre-trained Language Models (PLM) to establish strong baselines for future research in this domain. The dataset is available at The dataset is available at https: //blog.thedeep.io/humset/.
PP-StructureV2: A Stronger Document Analysis System
Oct 11, 2022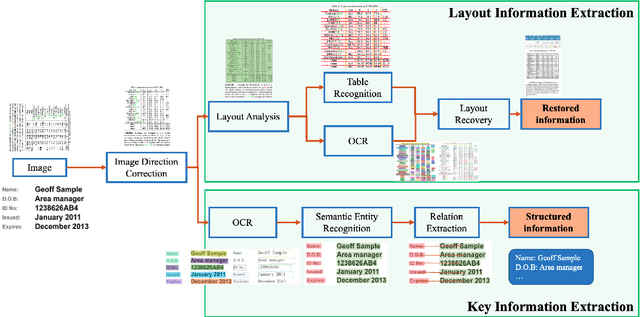



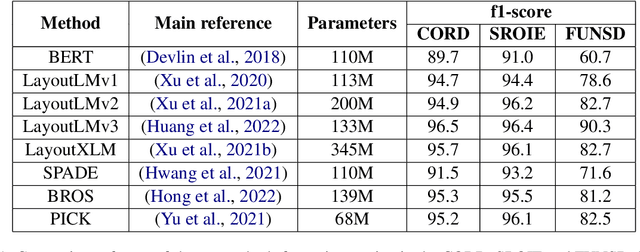
A large amount of document data exists in unstructured form such as raw images without any text information. Designing a practical document image analysis system is a meaningful but challenging task. In previous work, we proposed an intelligent document analysis system PP-Structure. In order to further upgrade the function and performance of PP-Structure, we propose PP-StructureV2 in this work, which contains two subsystems: Layout Information Extraction and Key Information Extraction. Firstly, we integrate Image Direction Correction module and Layout Restoration module to enhance the functionality of the system. Secondly, 8 practical strategies are utilized in PP-StructureV2 for better performance. For Layout Analysis model, we introduce ultra light-weight detector PP-PicoDet and knowledge distillation algorithm FGD for model lightweighting, which increased the inference speed by 11 times with comparable mAP. For Table Recognition model, we utilize PP-LCNet, CSP-PAN and SLAHead to optimize the backbone module, feature fusion module and decoding module, respectively, which improved the table structure accuracy by 6\% with comparable inference speed. For Key Information Extraction model, we introduce VI-LayoutXLM which is a visual-feature independent LayoutXLM architecture, TB-YX sorting algorithm and U-DML knowledge distillation algorithm, which brought 2.8\% and 9.1\% improvement respectively on the Hmean of Semantic Entity Recognition and Relation Extraction tasks. All the above mentioned models and code are open-sourced in the GitHub repository PaddleOCR.
An Empirical Study on Finding Spans
Oct 14, 2022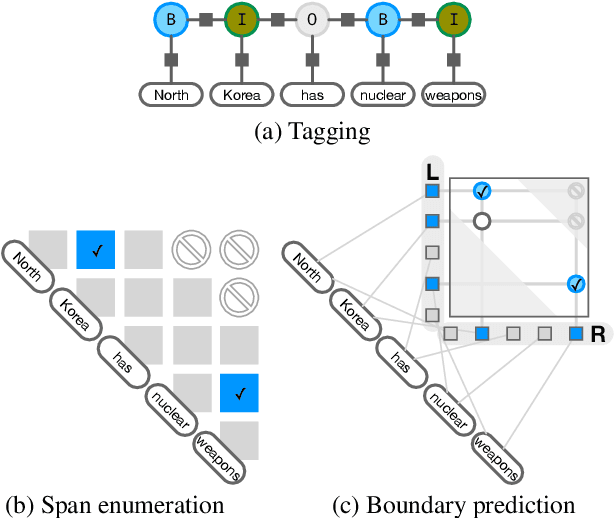
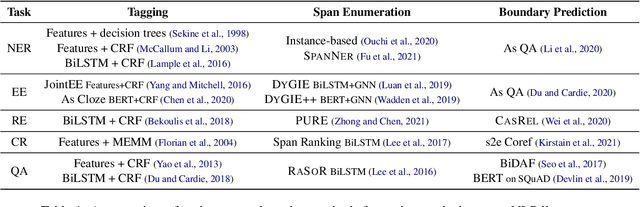
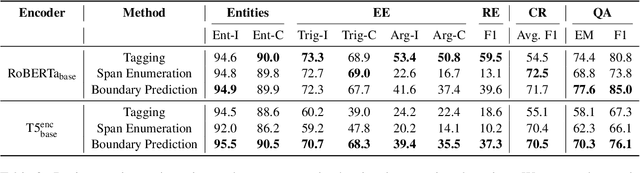
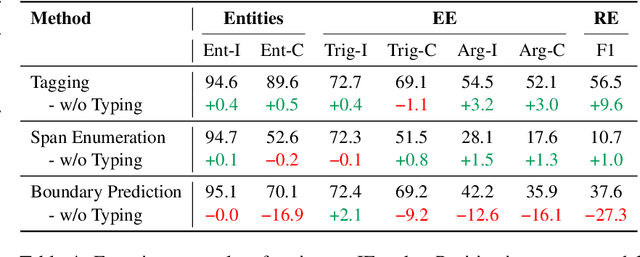
We present an empirical study on methods for span finding, the selection of consecutive tokens in text for some downstream tasks. We focus on approaches that can be employed in training end-to-end information extraction systems, and find there is no definitive solution without considering task properties, and provide our observations to help with future design choices: 1) a tagging approach often yields higher precision while span enumeration and boundary prediction provide higher recall; 2) span type information can benefit a boundary prediction approach; 3) additional contextualization does not help span finding in most cases.
Content-based Graph Privacy Advisor
Oct 20, 2022
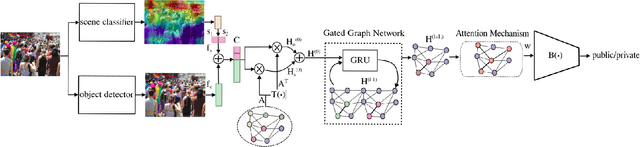


People may be unaware of the privacy risks of uploading an image online. In this paper, we present an image privacy classifier that uses scene information and object cardinality as cues for the prediction of image privacy. Our Graph Privacy Advisor (GPA) model simplifies a state-of-the-art graph model and improves its performance by refining the relevance of the content-based information extracted from the image. We determine the most informative visual features to be used for the privacy classification task and reduce the complexity of the model by replacing high-dimensional image-based feature vectors with lower-dimensional, more effective features. We also address the biased prior information by modelling object co-occurrences instead of the frequency of object occurrences in each class.
Symmetry and Variance: Generative Parametric Modelling of Historical Brick Wall Patterns
Oct 23, 2022
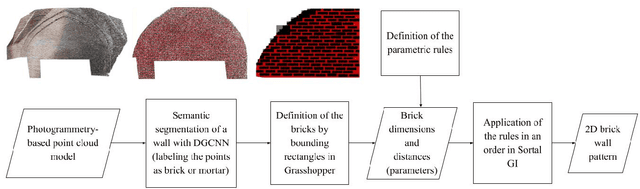

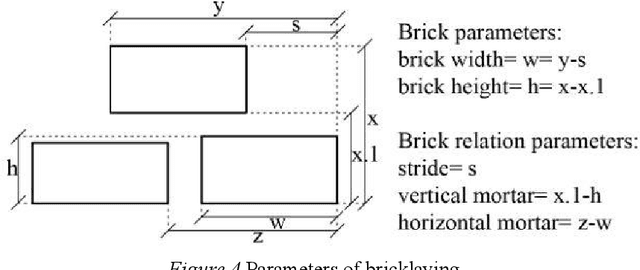
This study integrates artificial intelligence and computational design tools to extract information from architectural heritage. Photogrammetry-based point cloud models of brick walls from the Anatolian Seljuk period are analysed in terms of the interrelated units of construction, simultaneously considering both the inherent symmetries and irregularities. The real-world data is used as input for acquiring the stochastic parameters of spatial relations and a set of parametric shape rules to recreate designs of existing and hypothetical brick walls within the style. The motivation is to be able to generate large data sets for machine learning of the style and to devise procedures for robotic production of such designs with repetitive units.
* 10 pages, 7 Figures. This paper is published at "Symmetry: Art and Science | 12th SIS-Symmetry Congress"
Graph sampling for node embedding
Oct 19, 2022
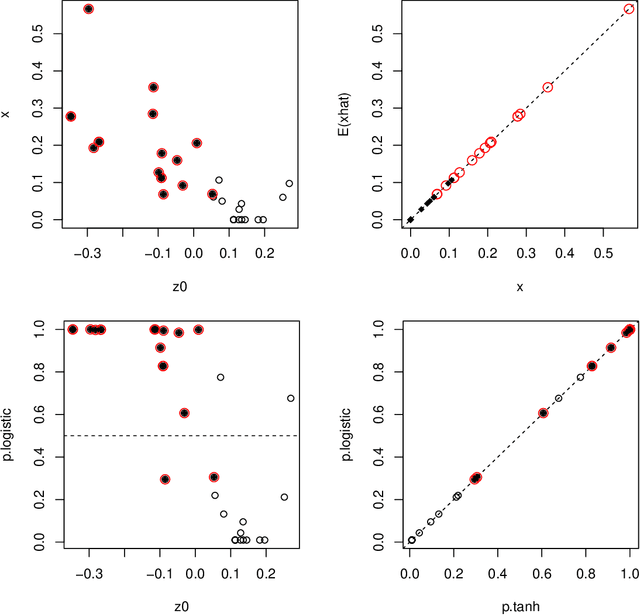
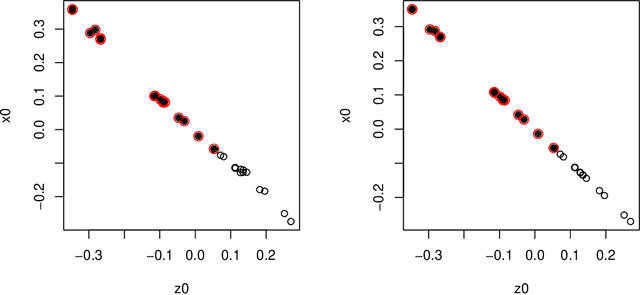
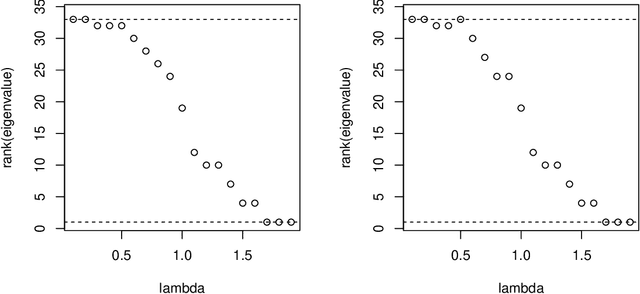
Node embedding is a central topic in graph representation learning. Computational efficiency and scalability can be challenging to any method that requires full-graph operations. We propose sampling approaches to node embedding, with or without explicit modelling of the feature vector, which aim to extract useful information from both the eigenvectors related to the graph Laplacien and the given values associated with the graph.