 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLing Shao
StyleGaussian: Instant 3D Style Transfer with Gaussian Splatting
Mar 12, 2024

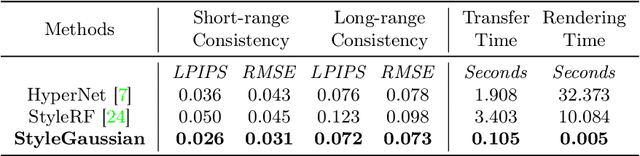

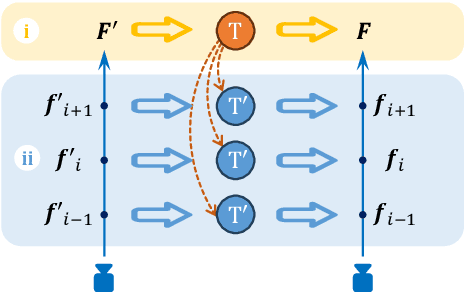
We introduce StyleGaussian, a novel 3D style transfer technique that allows instant transfer of any image's style to a 3D scene at 10 frames per second (fps). Leveraging 3D Gaussian Splatting (3DGS), StyleGaussian achieves style transfer without compromising its real-time rendering ability and multi-view consistency. It achieves instant style transfer with three steps: embedding, transfer, and decoding. Initially, 2D VGG scene features are embedded into reconstructed 3D Gaussians. Next, the embedded features are transformed according to a reference style image. Finally, the transformed features are decoded into the stylized RGB. StyleGaussian has two novel designs. The first is an efficient feature rendering strategy that first renders low-dimensional features and then maps them into high-dimensional features while embedding VGG features. It cuts the memory consumption significantly and enables 3DGS to render the high-dimensional memory-intensive features. The second is a K-nearest-neighbor-based 3D CNN. Working as the decoder for the stylized features, it eliminates the 2D CNN operations that compromise strict multi-view consistency. Extensive experiments show that StyleGaussian achieves instant 3D stylization with superior stylization quality while preserving real-time rendering and strict multi-view consistency. Project page: https://kunhao-liu.github.io/StyleGaussian/
Latent Semantic Consensus For Deterministic Geometric Model Fitting
Mar 11, 2024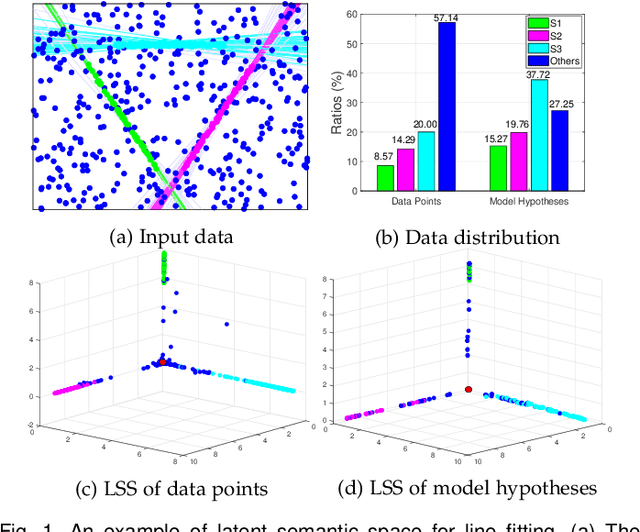
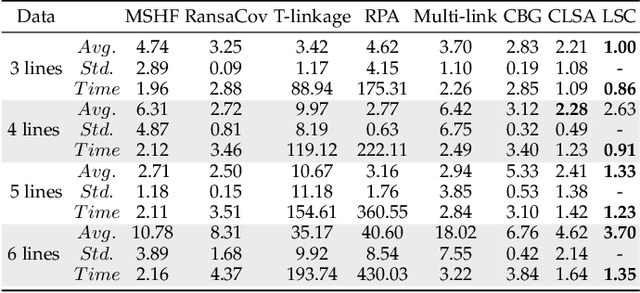
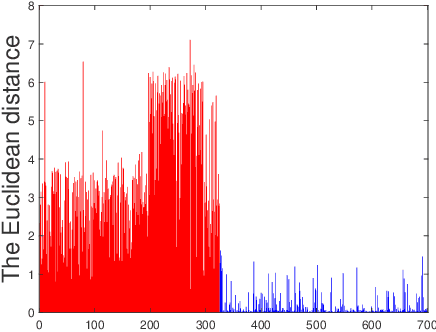
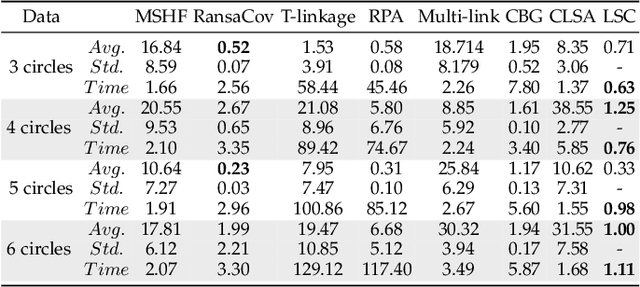
Estimating reliable geometric model parameters from the data with severe outliers is a fundamental and important task in computer vision. This paper attempts to sample high-quality subsets and select model instances to estimate parameters in the multi-structural data. To address this, we propose an effective method called Latent Semantic Consensus (LSC). The principle of LSC is to preserve the latent semantic consensus in both data points and model hypotheses. Specifically, LSC formulates the model fitting problem into two latent semantic spaces based on data points and model hypotheses, respectively. Then, LSC explores the distributions of points in the two latent semantic spaces, to remove outliers, generate high-quality model hypotheses, and effectively estimate model instances. Finally, LSC is able to provide consistent and reliable solutions within only a few milliseconds for general multi-structural model fitting, due to its deterministic fitting nature and efficiency. Compared with several state-of-the-art model fitting methods, our LSC achieves significant superiority for the performance of both accuracy and speed on synthetic data and real images. The code will be available at https://github.com/guobaoxiao/LSC.
Delving into Multi-modal Multi-task Foundation Models for Road Scene Understanding: From Learning Paradigm Perspectives
Feb 05, 2024Foundation models have indeed made a profound impact on various fields, emerging as pivotal components that significantly shape the capabilities of intelligent systems. In the context of intelligent vehicles, leveraging the power of foundation models has proven to be transformative, offering notable advancements in visual understanding. Equipped with multi-modal and multi-task learning capabilities, multi-modal multi-task visual understanding foundation models (MM-VUFMs) effectively process and fuse data from diverse modalities and simultaneously handle various driving-related tasks with powerful adaptability, contributing to a more holistic understanding of the surrounding scene. In this survey, we present a systematic analysis of MM-VUFMs specifically designed for road scenes. Our objective is not only to provide a comprehensive overview of common practices, referring to task-specific models, unified multi-modal models, unified multi-task models, and foundation model prompting techniques, but also to highlight their advanced capabilities in diverse learning paradigms. These paradigms include open-world understanding, efficient transfer for road scenes, continual learning, interactive and generative capability. Moreover, we provide insights into key challenges and future trends, such as closed-loop driving systems, interpretability, embodied driving agents, and world models. To facilitate researchers in staying abreast of the latest developments in MM-VUFMs for road scenes, we have established a continuously updated repository at https://github.com/rolsheng/MM-VUFM4DS
Graph Transformer GANs with Graph Masked Modeling for Architectural Layout Generation
Jan 15, 2024We present a novel graph Transformer generative adversarial network (GTGAN) to learn effective graph node relations in an end-to-end fashion for challenging graph-constrained architectural layout generation tasks. The proposed graph-Transformer-based generator includes a novel graph Transformer encoder that combines graph convolutions and self-attentions in a Transformer to model both local and global interactions across connected and non-connected graph nodes. Specifically, the proposed connected node attention (CNA) and non-connected node attention (NNA) aim to capture the global relations across connected nodes and non-connected nodes in the input graph, respectively. The proposed graph modeling block (GMB) aims to exploit local vertex interactions based on a house layout topology. Moreover, we propose a new node classification-based discriminator to preserve the high-level semantic and discriminative node features for different house components. To maintain the relative spatial relationships between ground truth and predicted graphs, we also propose a novel graph-based cycle-consistency loss. Finally, we propose a novel self-guided pre-training method for graph representation learning. This approach involves simultaneous masking of nodes and edges at an elevated mask ratio (i.e., 40%) and their subsequent reconstruction using an asymmetric graph-centric autoencoder architecture. This method markedly improves the model's learning proficiency and expediency. Experiments on three challenging graph-constrained architectural layout generation tasks (i.e., house layout generation, house roof generation, and building layout generation) with three public datasets demonstrate the effectiveness of the proposed method in terms of objective quantitative scores and subjective visual realism. New state-of-the-art results are established by large margins on these three tasks.
Domain Adaptation for Large-Vocabulary Object Detectors
Jan 13, 2024Large-vocabulary object detectors (LVDs) aim to detect objects of many categories, which learn super objectness features and can locate objects accurately while applied to various downstream data. However, LVDs often struggle in recognizing the located objects due to domain discrepancy in data distribution and object vocabulary. At the other end, recent vision-language foundation models such as CLIP demonstrate superior open-vocabulary recognition capability. This paper presents KGD, a Knowledge Graph Distillation technique that exploits the implicit knowledge graphs (KG) in CLIP for effectively adapting LVDs to various downstream domains. KGD consists of two consecutive stages: 1) KG extraction that employs CLIP to encode downstream domain data as nodes and their feature distances as edges, constructing KG that inherits the rich semantic relations in CLIP explicitly; and 2) KG encapsulation that transfers the extracted KG into LVDs to enable accurate cross-domain object classification. In addition, KGD can extract both visual and textual KG independently, providing complementary vision and language knowledge for object localization and object classification in detection tasks over various downstream domains. Experiments over multiple widely adopted detection benchmarks show that KGD outperforms the state-of-the-art consistently by large margins.
DA-BEV: Unsupervised Domain Adaptation for Bird's Eye View Perception
Jan 13, 2024Camera-only Bird's Eye View (BEV) has demonstrated great potential in environment perception in a 3D space. However, most existing studies were conducted under a supervised setup which cannot scale well while handling various new data. Unsupervised domain adaptive BEV, which effective learning from various unlabelled target data, is far under-explored. In this work, we design DA-BEV, the first domain adaptive camera-only BEV framework that addresses domain adaptive BEV challenges by exploiting the complementary nature of image-view features and BEV features. DA-BEV introduces the idea of query into the domain adaptation framework to derive useful information from image-view and BEV features. It consists of two query-based designs, namely, query-based adversarial learning (QAL) and query-based self-training (QST), which exploits image-view features or BEV features to regularize the adaptation of the other. Extensive experiments show that DA-BEV achieves superior domain adaptive BEV perception performance consistently across multiple datasets and tasks such as 3D object detection and 3D scene segmentation.
ECEA: Extensible Co-Existing Attention for Few-Shot Object Detection
Sep 15, 2023
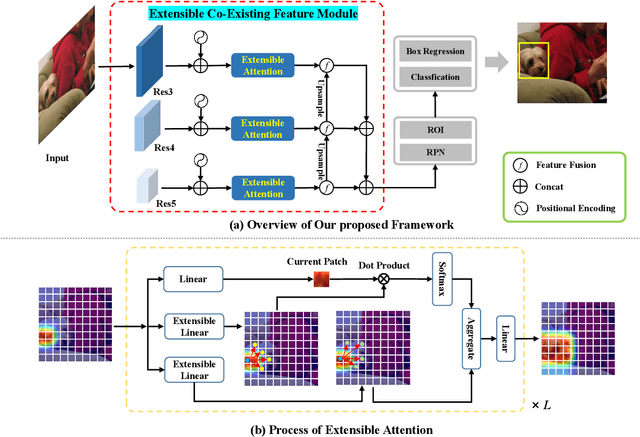
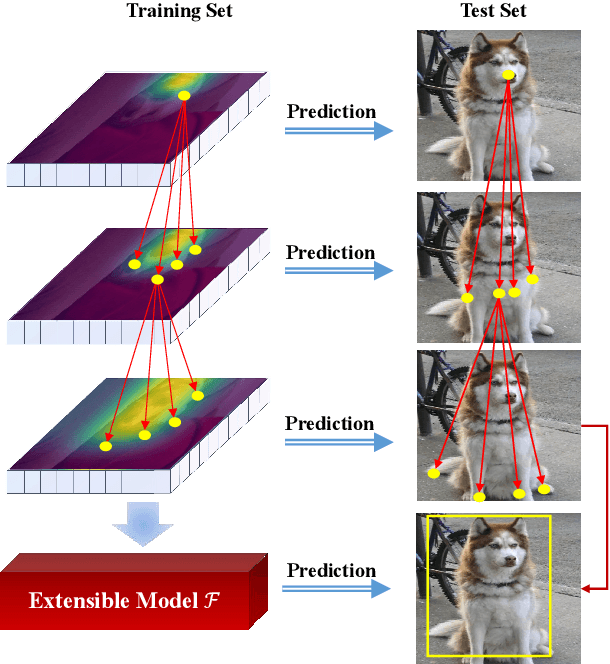
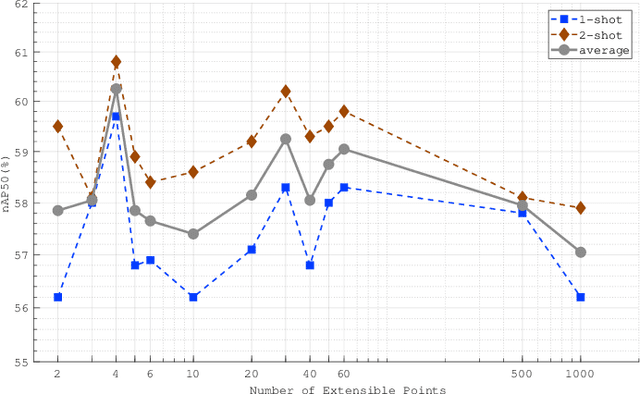
Few-shot object detection (FSOD) identifies objects from extremely few annotated samples. Most existing FSOD methods, recently, apply the two-stage learning paradigm, which transfers the knowledge learned from abundant base classes to assist the few-shot detectors by learning the global features. However, such existing FSOD approaches seldom consider the localization of objects from local to global. Limited by the scarce training data in FSOD, the training samples of novel classes typically capture part of objects, resulting in such FSOD methods cannot detect the completely unseen object during testing. To tackle this problem, we propose an Extensible Co-Existing Attention (ECEA) module to enable the model to infer the global object according to the local parts. Essentially, the proposed module continuously learns the extensible ability on the base stage with abundant samples and transfers it to the novel stage, which can assist the few-shot model to quickly adapt in extending local regions to co-existing regions. Specifically, we first devise an extensible attention mechanism that starts with a local region and extends attention to co-existing regions that are similar and adjacent to the given local region. We then implement the extensible attention mechanism in different feature scales to progressively discover the full object in various receptive fields. Extensive experiments on the PASCAL VOC and COCO datasets show that our ECEA module can assist the few-shot detector to completely predict the object despite some regions failing to appear in the training samples and achieve the new state of the art compared with existing FSOD methods.
Pose-Free Neural Radiance Fields via Implicit Pose Regularization
Aug 29, 2023
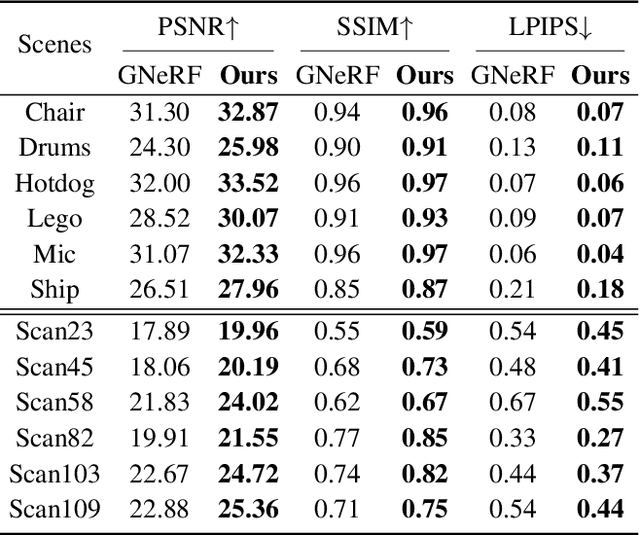
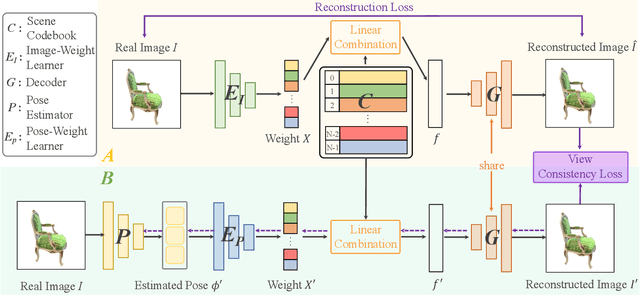
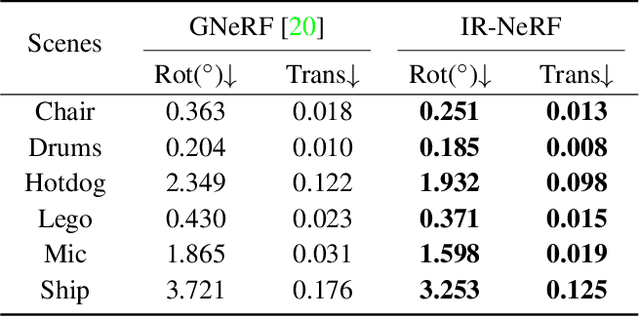
Pose-free neural radiance fields (NeRF) aim to train NeRF with unposed multi-view images and it has achieved very impressive success in recent years. Most existing works share the pipeline of training a coarse pose estimator with rendered images at first, followed by a joint optimization of estimated poses and neural radiance field. However, as the pose estimator is trained with only rendered images, the pose estimation is usually biased or inaccurate for real images due to the domain gap between real images and rendered images, leading to poor robustness for the pose estimation of real images and further local minima in joint optimization. We design IR-NeRF, an innovative pose-free NeRF that introduces implicit pose regularization to refine pose estimator with unposed real images and improve the robustness of the pose estimation for real images. With a collection of 2D images of a specific scene, IR-NeRF constructs a scene codebook that stores scene features and captures the scene-specific pose distribution implicitly as priors. Thus, the robustness of pose estimation can be promoted with the scene priors according to the rationale that a 2D real image can be well reconstructed from the scene codebook only when its estimated pose lies within the pose distribution. Extensive experiments show that IR-NeRF achieves superior novel view synthesis and outperforms the state-of-the-art consistently across multiple synthetic and real datasets.
COCA: Classifier-Oriented Calibration for Source-Free Universal Domain Adaptation via Textual Prototype
Aug 21, 2023
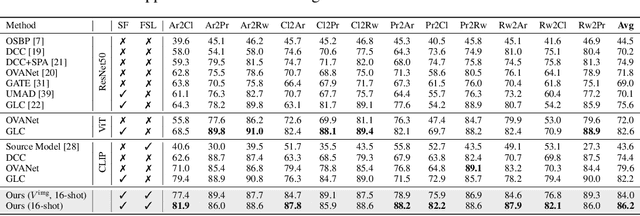
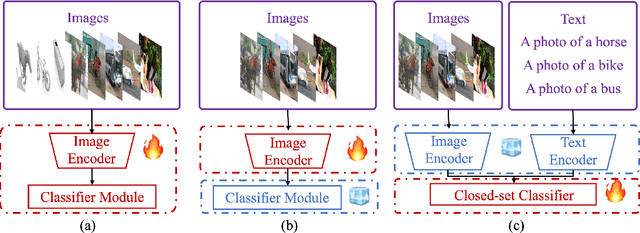
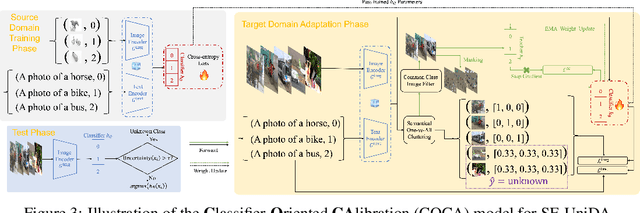
Universal Domain Adaptation (UniDA) aims to distinguish common and private classes between the source and target domains where domain shift exists. Recently, due to more stringent data restrictions, researchers have introduced Source-Free UniDA (SF-UniDA) in more realistic scenarios. SF-UniDA methods eliminate the need for direct access to source samples when performing adaptation to the target domain. However, existing SF-UniDA methods still require an extensive quantity of labeled source samples to train a source model, resulting in significant labeling costs. To tackle this issue, we present a novel Classifier-Oriented Calibration (COCA) method. This method, which leverages textual prototypes, is formulated for the source model based on few-shot learning. Specifically, we propose studying few-shot learning, usually explored for closed-set scenarios, to identify common and domain-private classes despite a significant domain shift between source and target domains. Essentially, we present a novel paradigm based on the vision-language model to learn SF-UniDA and hugely reduce the labeling costs on the source domain. Experimental results demonstrate that our approach outperforms state-of-the-art UniDA and SF-UniDA models.
WaveNeRF: Wavelet-based Generalizable Neural Radiance Fields
Aug 09, 2023
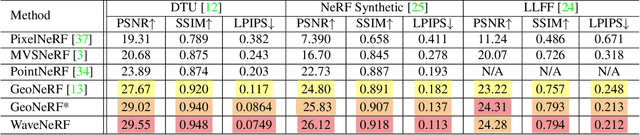
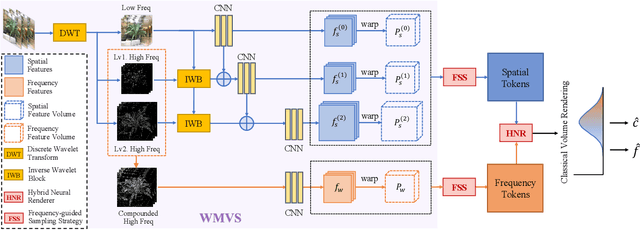

Neural Radiance Field (NeRF) has shown impressive performance in novel view synthesis via implicit scene representation. However, it usually suffers from poor scalability as requiring densely sampled images for each new scene. Several studies have attempted to mitigate this problem by integrating Multi-View Stereo (MVS) technique into NeRF while they still entail a cumbersome fine-tuning process for new scenes. Notably, the rendering quality will drop severely without this fine-tuning process and the errors mainly appear around the high-frequency features. In the light of this observation, we design WaveNeRF, which integrates wavelet frequency decomposition into MVS and NeRF to achieve generalizable yet high-quality synthesis without any per-scene optimization. To preserve high-frequency information when generating 3D feature volumes, WaveNeRF builds Multi-View Stereo in the Wavelet domain by integrating the discrete wavelet transform into the classical cascade MVS, which disentangles high-frequency information explicitly. With that, disentangled frequency features can be injected into classic NeRF via a novel hybrid neural renderer to yield faithful high-frequency details, and an intuitive frequency-guided sampling strategy can be designed to suppress artifacts around high-frequency regions. Extensive experiments over three widely studied benchmarks show that WaveNeRF achieves superior generalizable radiance field modeling when only given three images as input.